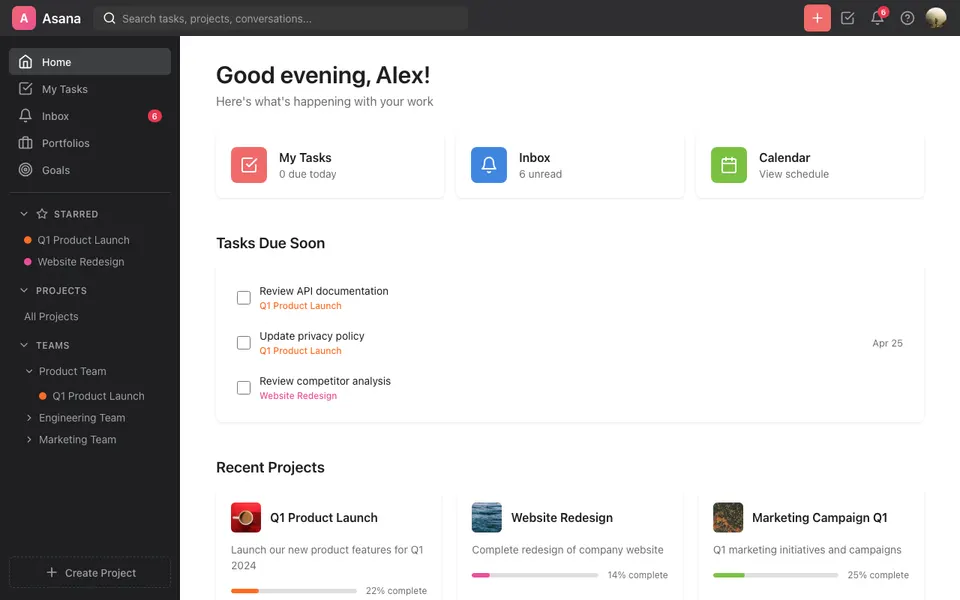
We Spent a Year Building Verifiable Training Tasks for GUI Agents. Here’s What We Learned.
RLVR has scaled in math and code. We tried to do the same for GUI agents: the problems we hit, the shortcuts that didn't work, and what actually did.
A year ago, watching RLVR drive generalization gains across SWE-bench and terminal-use, we became convinced that CUA post-training was seriously underexplored. The GUI surface is far richer than code or a shell: every app, every website, every SaaS tool a knowledge worker touches is a potential training environment, and unlike programming tasks, that surface keeps expanding.
The problem is that building verifiable training data for GUI is hard in ways that have no good analog in code. In SWE research, GitHub provides a natural corpus with built-in tests that serve as ground-truth reward signals. GUI has nothing equivalent. Real applications sit behind accounts, rate limits, and terms of service that make them far less accessible than sandboxed repos. And even when you can access them, there is no universal way to check whether a GUI task actually completed successfully. There is no test runner, no programmatic diff. We called these three barriers corpus scarcity, environment inaccessibility, and task unverifiability.
The obvious starting point was human annotation. We ran a study with PhD-level experts who understood the problem well. Each could produce around 3 to 5 verified tasks per working day. RLVR at any meaningful scale needs tens of thousands of tuples, so the numbers simply did not add up.
What was more interesting was what we observed while those experts were working. Almost without exception, they had Claude Code open in a side window, using it to draft reward scripts, running the scripts against the environment, fixing failures, and iterating. The human was not writing logic; they were acting as a harness, manually orchestrating a loop that the agent was already capable of running. The natural question was whether we could close that loop entirely.
An RLVR training tuple for CUA is a triple (t, s, r): a task instruction, a reproducible initial environment state, and a reward function. The challenge is that if you generate these three components independently, there is no guarantee they are consistent with each other. The reward might pass trivially on the initial state, or the environment setup might make the task impossible to complete. Prior approaches tried to filter or verify consistency after the fact. CUA-Gym instead generates all three from a single shared specification, so consistency is guaranteed by construction.
The key design choice is an information barrier between the Generator and Discriminator. The Generator proposes the full (task, environment, reward) triple; the Discriminator then verifies whether the reward actually tests what the task asks, but it cannot see the environment setup script. This forces the reward function to be grounded in the task semantics rather than the implementation details, which closes off the shortcut of simply re-checking what was just constructed.
Data Synthesis Pipeline
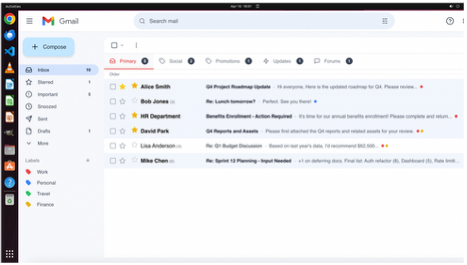
Task: Can you please send an email to each client listed in the opened Notion page using the template from Gmail? You should attach their transactions in the 'clients.xlsx' table on desktop.
Context: There should be 10 clients in the Notion database page, each with email listed, and an existing email template in the 'Sent' folder of Gmail. The spreadsheet 'clients.xlsx' is a complete document containing all clients during 2024 Q1–2025 Q4…
- Searching on Reddit
- "how do people use gmail…"
- ↳ 14 threads · 3 saved
- Reading Notion docs
- + Gmail templates
- ↳ 9 docs scanned
- Reading prepared assets
- images / pdfs / tables
- ↳ clients.xlsx loaded
- · difficulty
- · domain
- · involved apps
while not consensus: g = generator.run() reward = discriminator.run() if not consensus.check(): retry return (task, setup, reward)
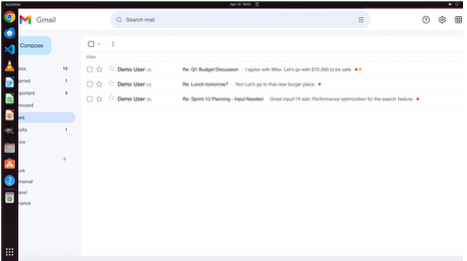
- · emails exist in Sent...
- · reward email content match template...
- · recipients match Notion DB...
- consistency92
- executability88
- hack-risk95
- clarity90
- difficulty76
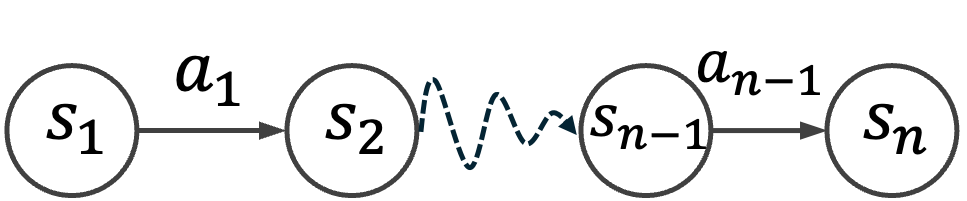
- ·Calculate
- ·Check
- ·Use VLM-as-a-judge to review
- ·Alignment check
We first ran this pipeline against the ten desktop applications in the OSWorld environment pool, generating roughly 10,000+ verified tuples. Trained on these, OpenCUA-72B climbed from around 50 to 59 on OSWorld, which validated that automated co-generation could work. For a moment, it felt like the problem was solved.
But ten applications is a benchmark, not a training distribution. The whole premise of CUA post-training is that the GUI surface is vast, and if training is confined to ten apps, the model has experienced a negligible fraction of it. We had validated the pipeline; we had not yet validated the thesis.
Expanding coverage along the environment axis meant confronting the same accessibility problem from the motivation section, now at larger scale. Real users spend their days in Gmail, Slack, Notion, Salesforce, and dozens of domain-specific tools that no benchmark has ever covered. We tried to instrument some of these directly, building wrappers around live services and scripting account provisioning. The approach did not hold at training scale: parallel rollouts require fresh, isolated environment state on demand, and real applications simply cannot provide that.
The insight that unblocked us was that CUA models do not actually need authentic environments. They need surfaces that behave like the real thing at the interaction level, with state that can be injected, inspected, and reset programmatically. We applied the same coding-agent loop from the reward-generation pipeline to environment synthesis: a Plan Agent drafts the application spec and UI traversal tree, a Dev Agent implements it as a self-contained SPA, and a Web Agent runs Playwright against the live mock, feeds discrepancies back, and iterates until behavior converges.
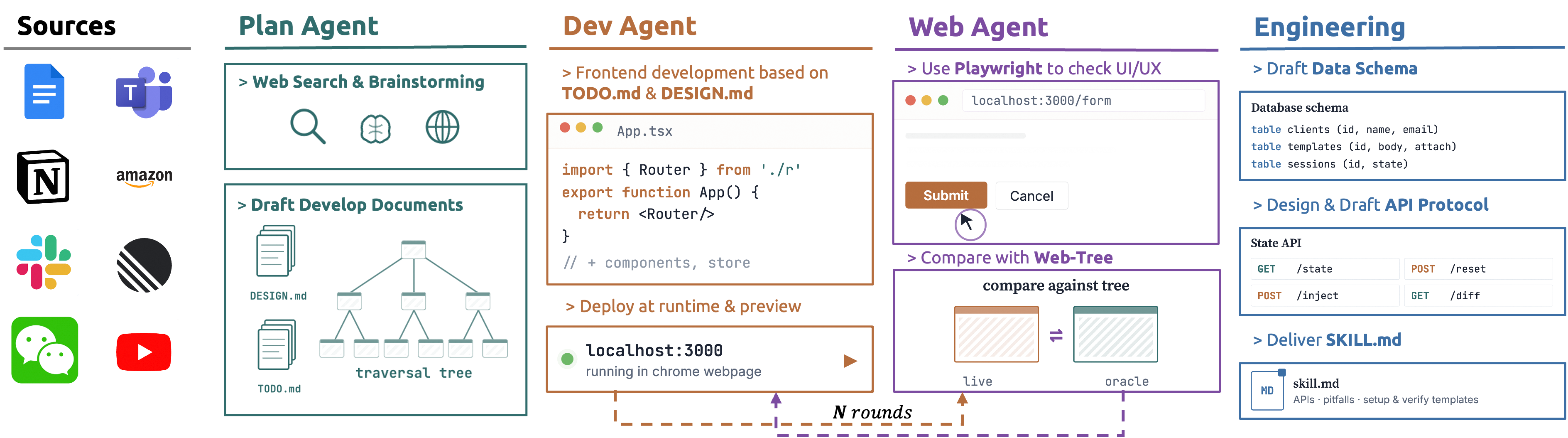
This produced 94 mock web applications covering communication, productivity, finance, developer tooling, and e-commerce. Combined with the 16 desktop applications from OSWorld, that gives us 110 environments and 32,122 verified RLVR tuples, the largest open CUA training corpus to date.
One thing the pipeline made viscerally clear: once reward generation is automated and environments are reliable, the bottleneck shifts entirely to the queries. A good query for CUA is not just a well-formed instruction. It requires careful thought about what capability it exercises, what difficulty level it targets, and what the initial environment context looks like before the agent starts. Generating a rich, grounded environment context alongside a realistic task description turned out to be significantly harder and more impactful than getting the reward annotation right.
We partially addressed this by grounding query generation in tutorials, online forums, and prepared asset files, which helped calibrate task realism and difficulty. But there is substantial room to improve. Scaling truly difficult, long-horizon queries that reflect how people actually use computers remains an open problem, and one we believe deserves deeper design and research attention.
| Dataset | Platform | Data size | Env. size | Reward | Open |
|---|---|---|---|---|---|
| GUI-Genesis[7] | Mobile | 969 | 1 | Programmatic | No |
| WebArena-Infinity[38] | Web | 1,260 | 10 | Programmatic | Yes |
| InfiniteWeb[36] | Web | 600 | — | Programmatic | No★ |
| UltraCUA[35] | Desktop | 17,000 | 9 | Programmatic | No★ |
| Gym-Anything[1] | Desktop | 7,277 | 193 | VLM | Yes |
| ▸CUA-Gym | Desktop + Web | 32,122 | 110 | Programmatic | Yes |
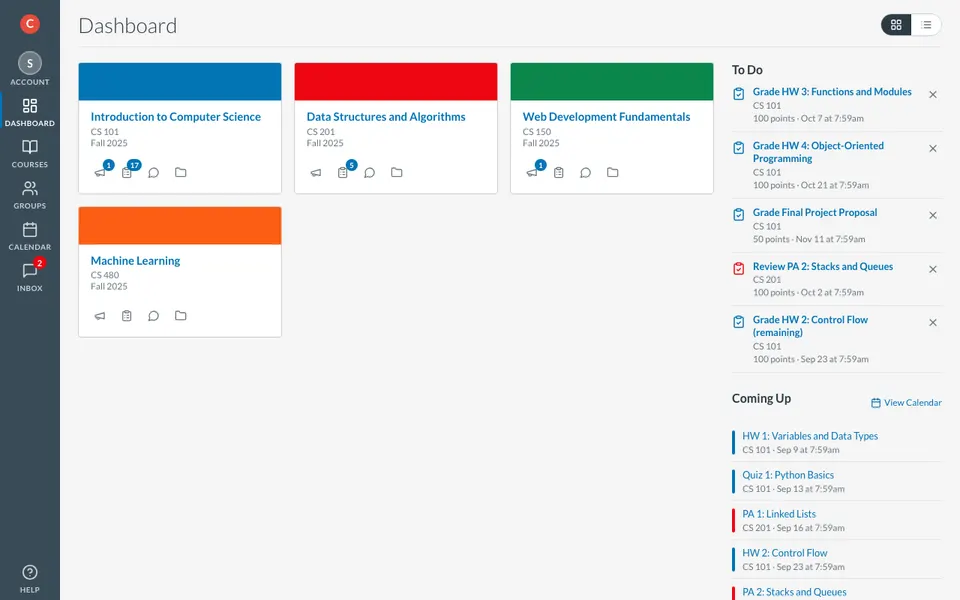
CUA-Gym-Hub is a suite of 99 self-contained mock applications, each implemented as a single-page React app backed by a unified state-injection / inspection / reset API. Targets are sampled from O*NET occupational taxonomies and the Anthropic Economic Index, biasing coverage toward applications used in real digital knowledge work. Click any thumbnail to open a live session.
Communication & Social
18
Productivity & Documents
17
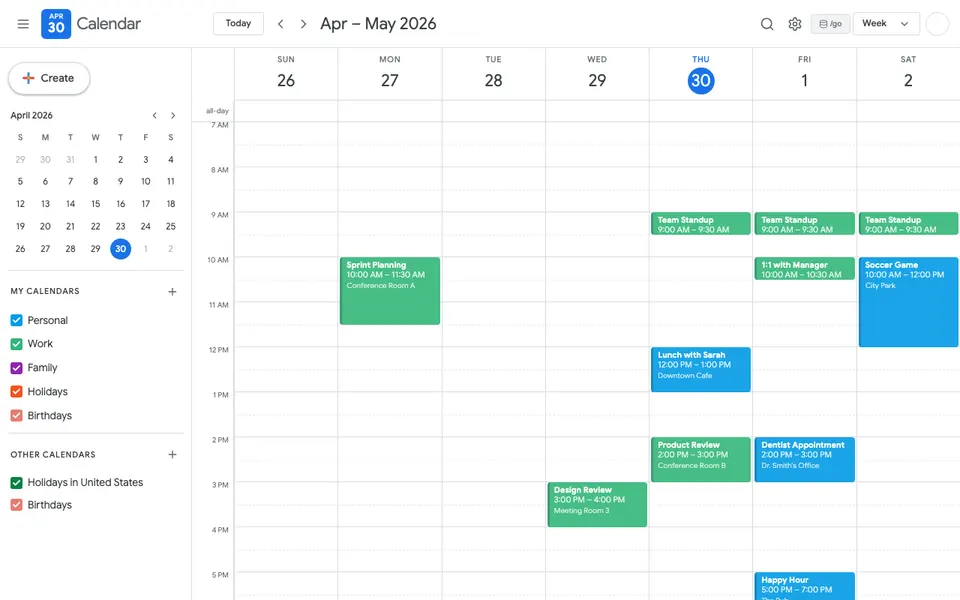
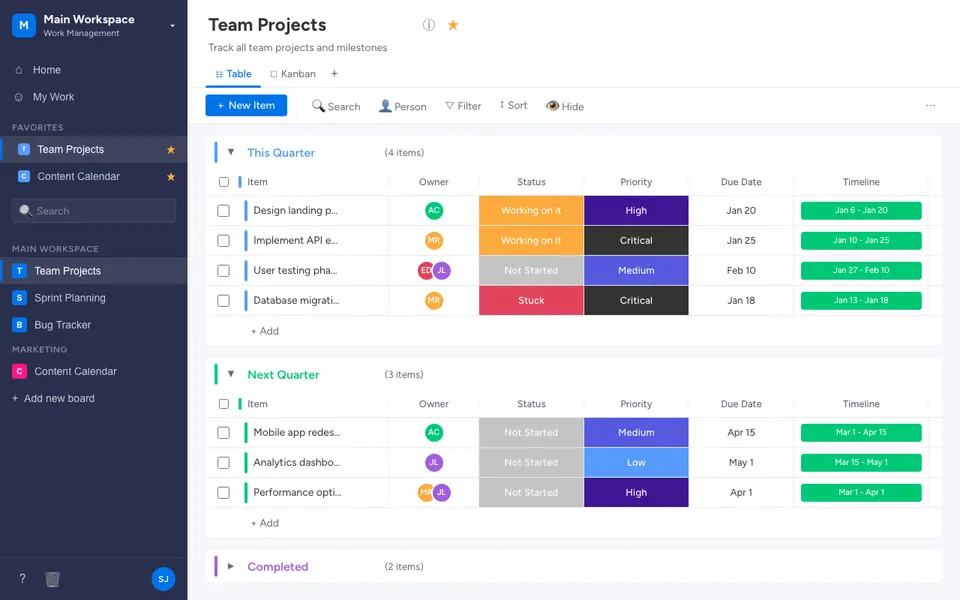
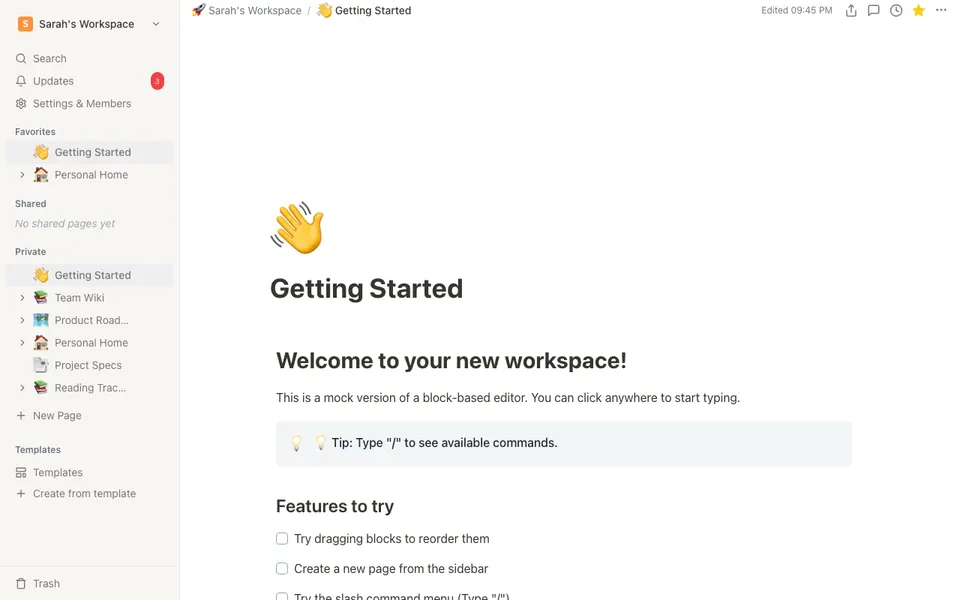
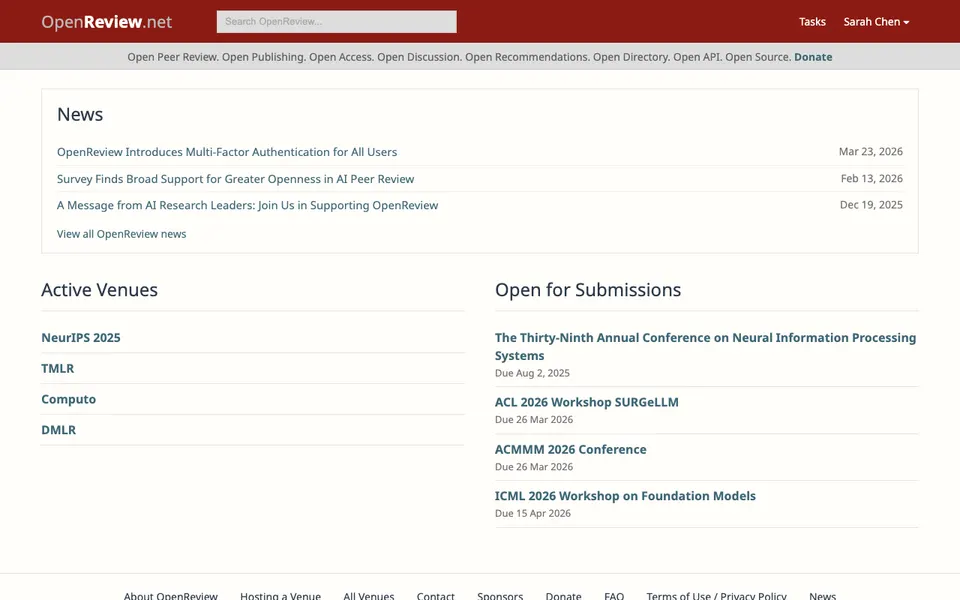
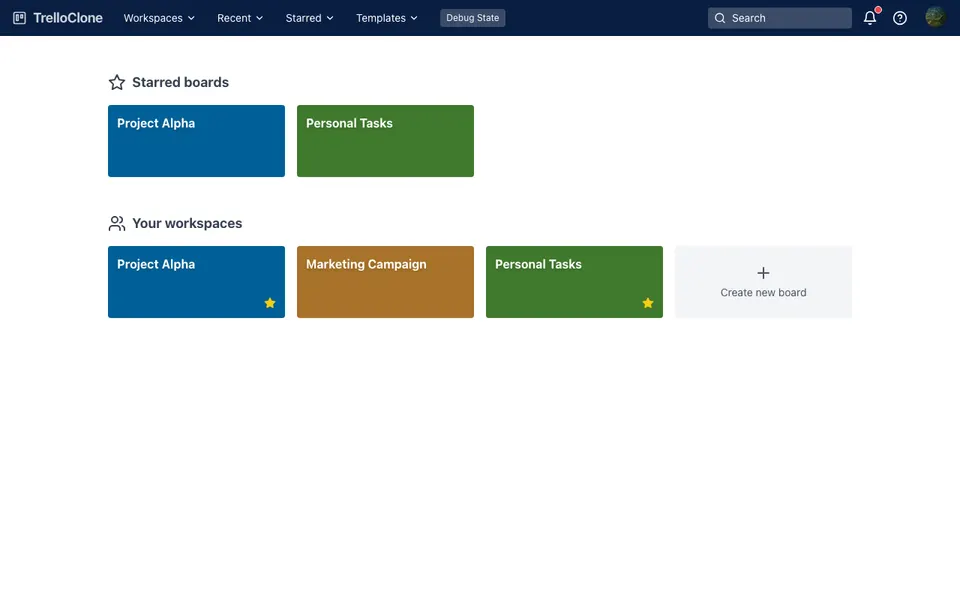
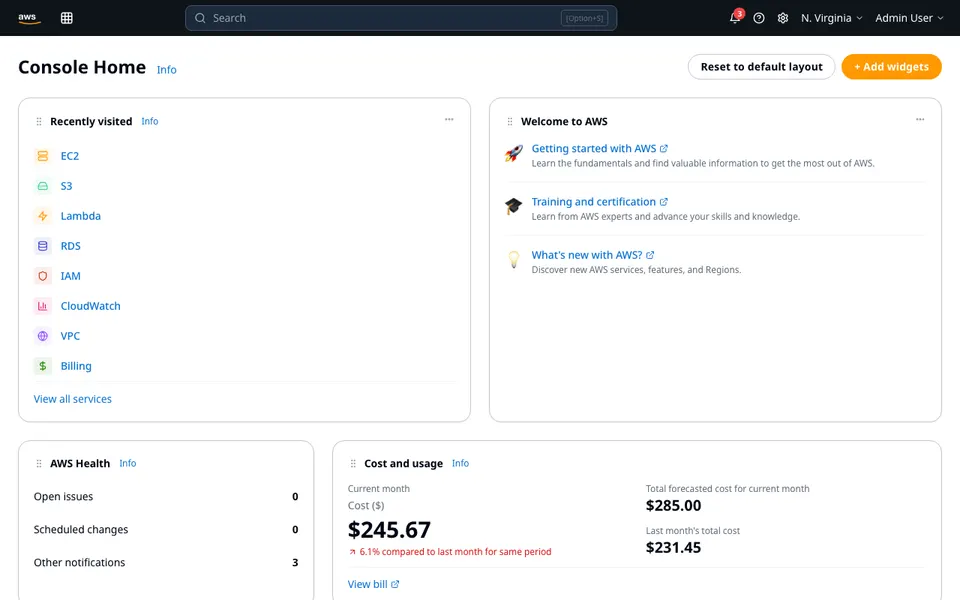
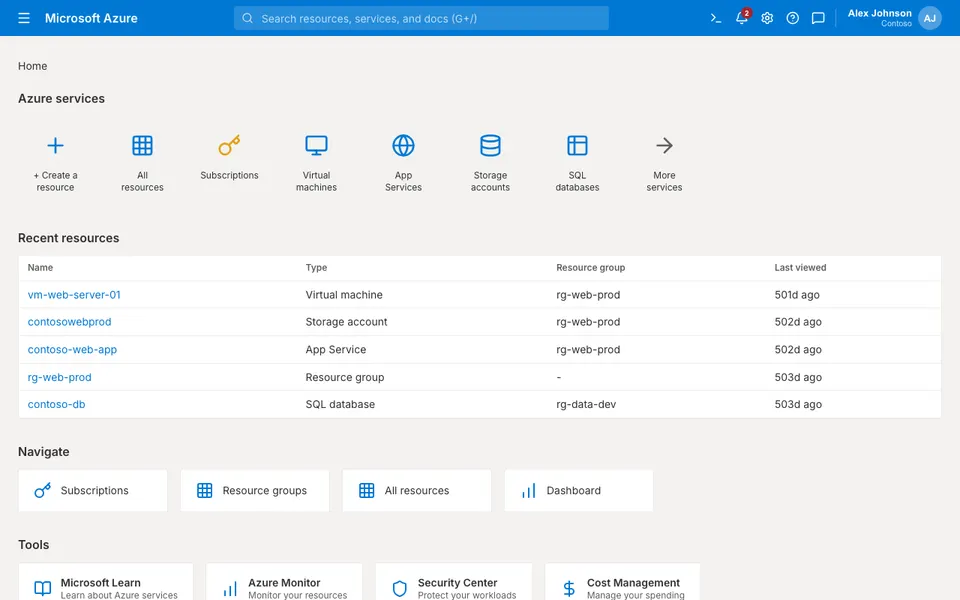
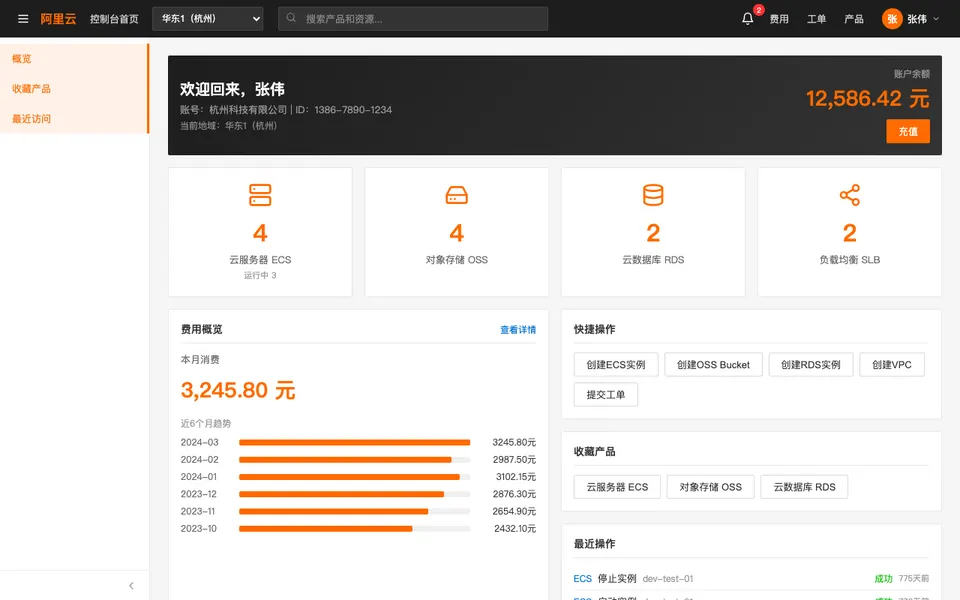
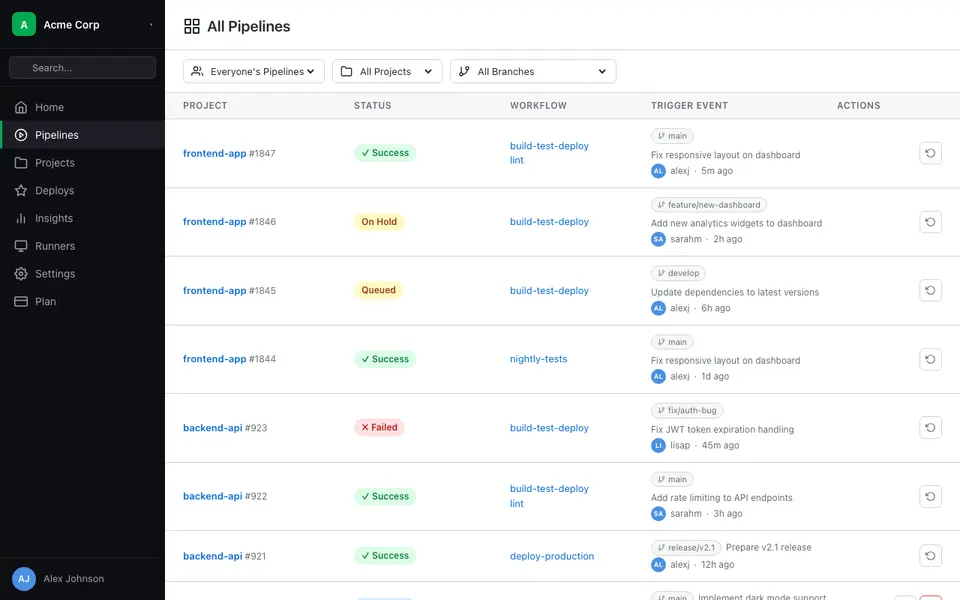
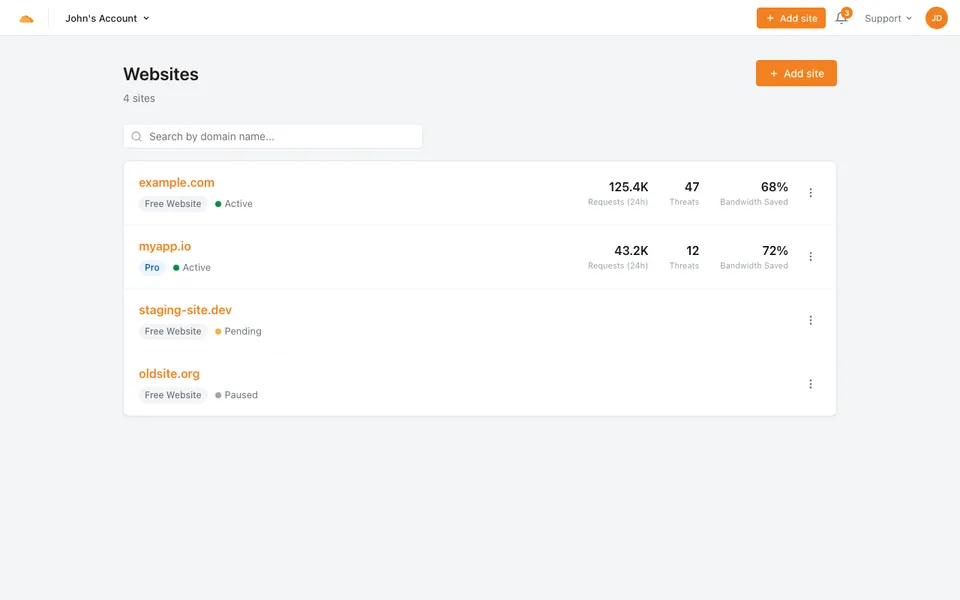
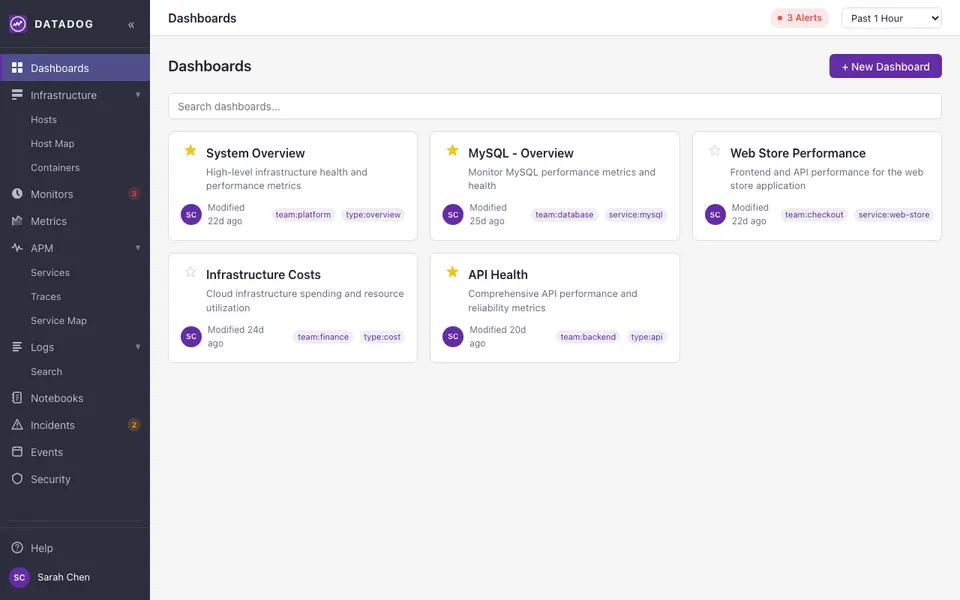
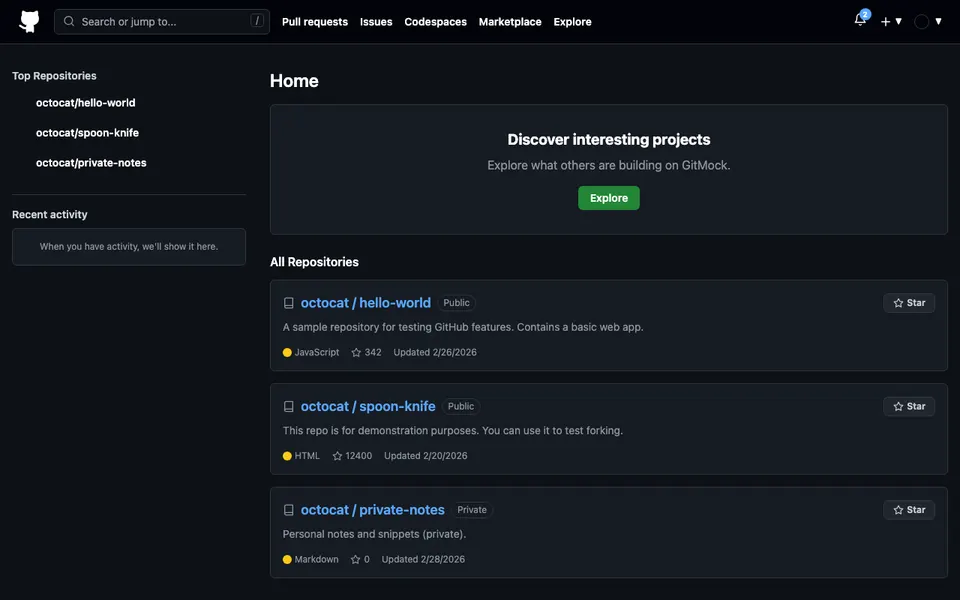
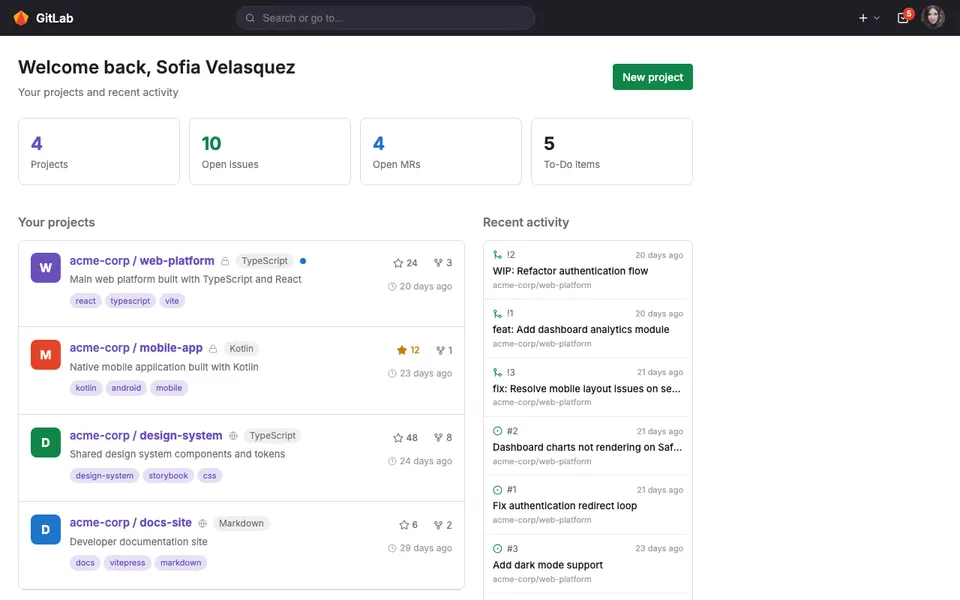
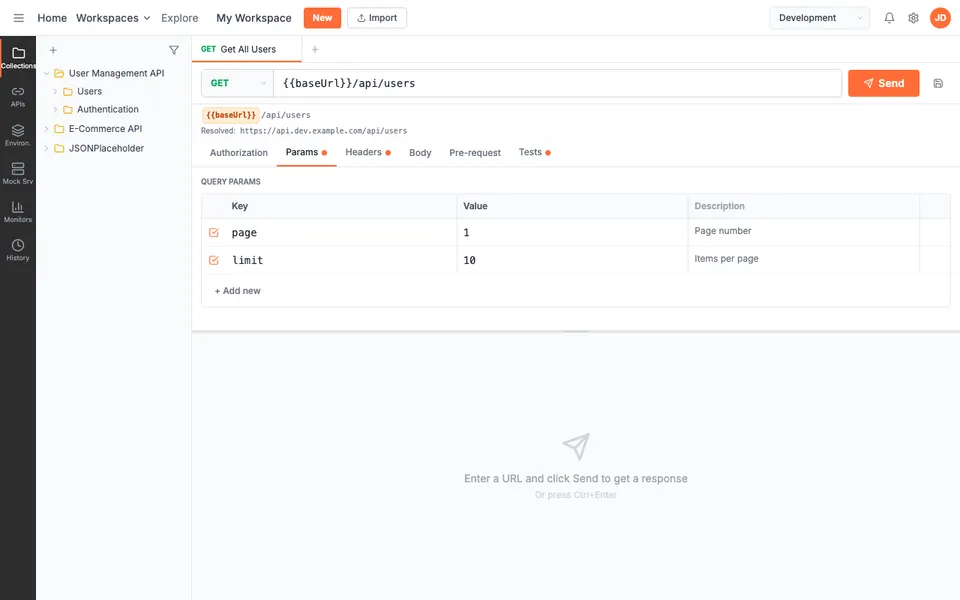
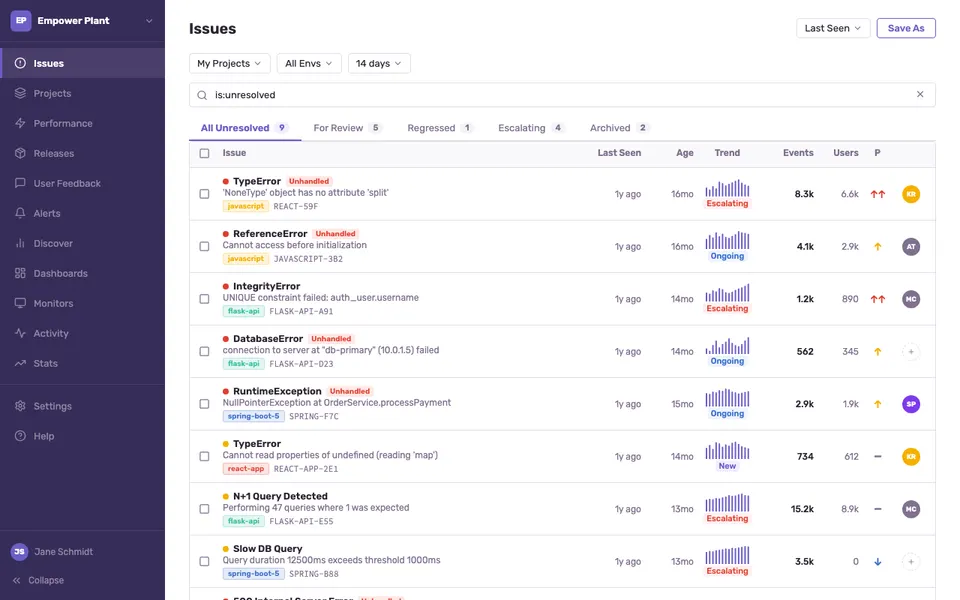
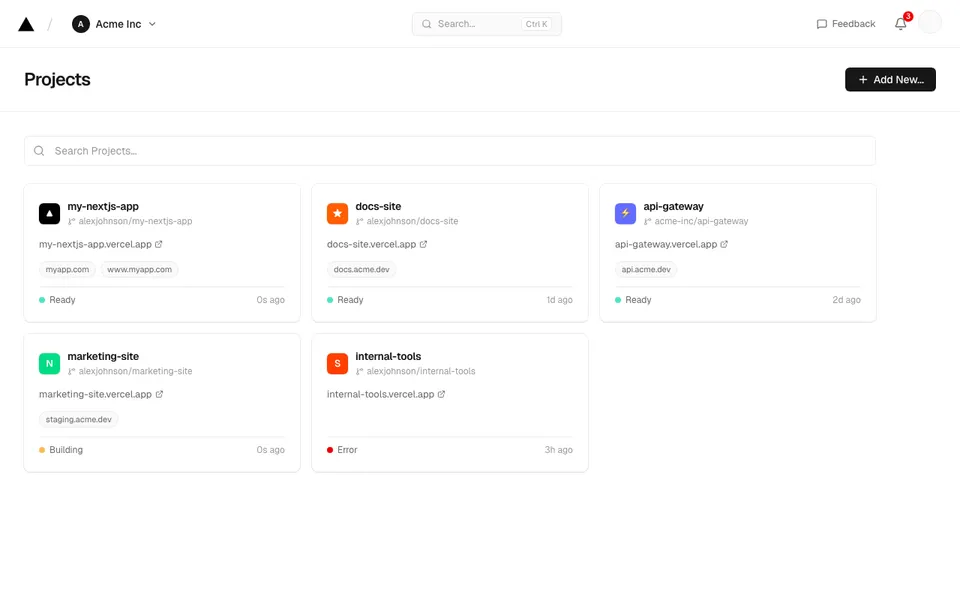
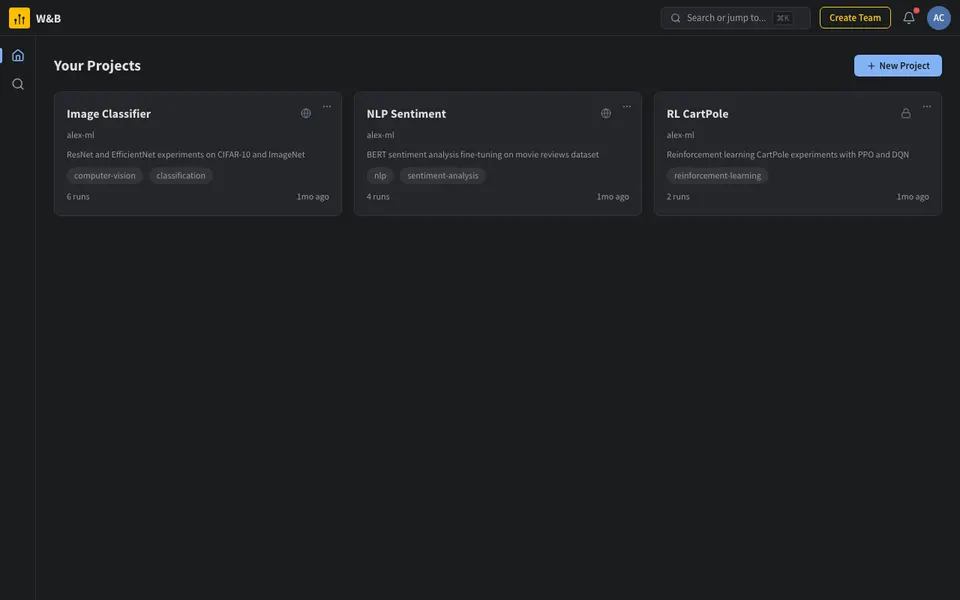
Finance & Enterprise
21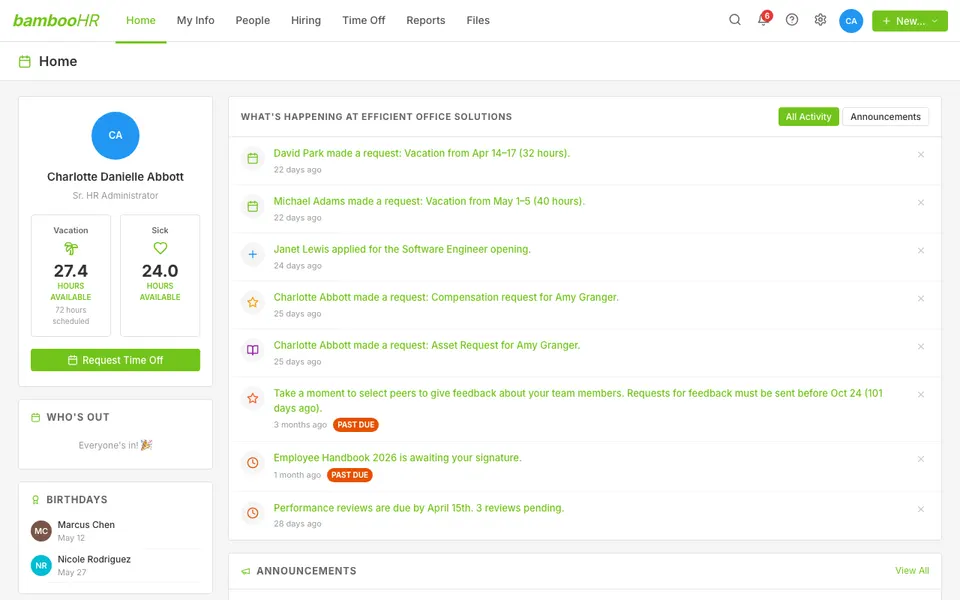
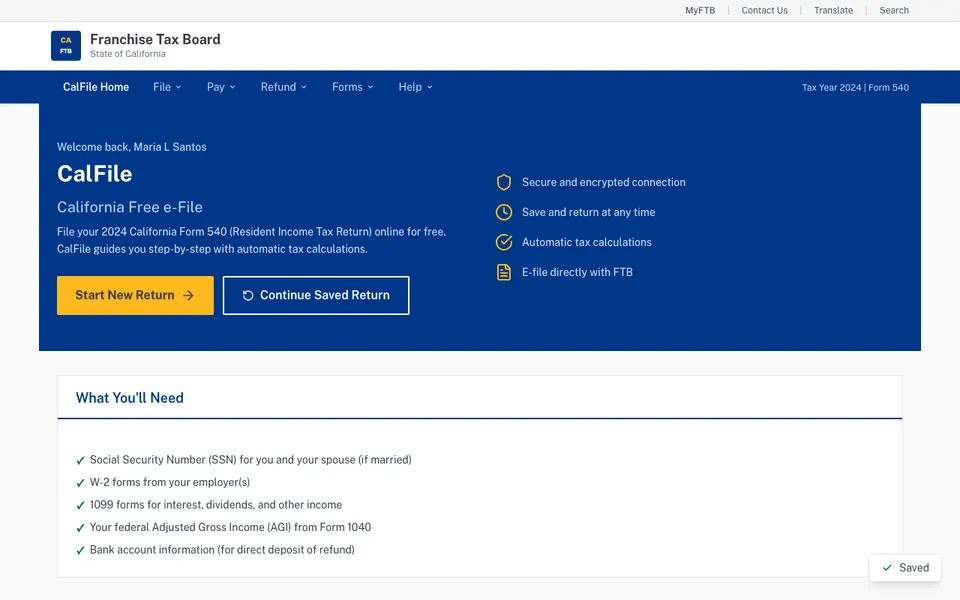
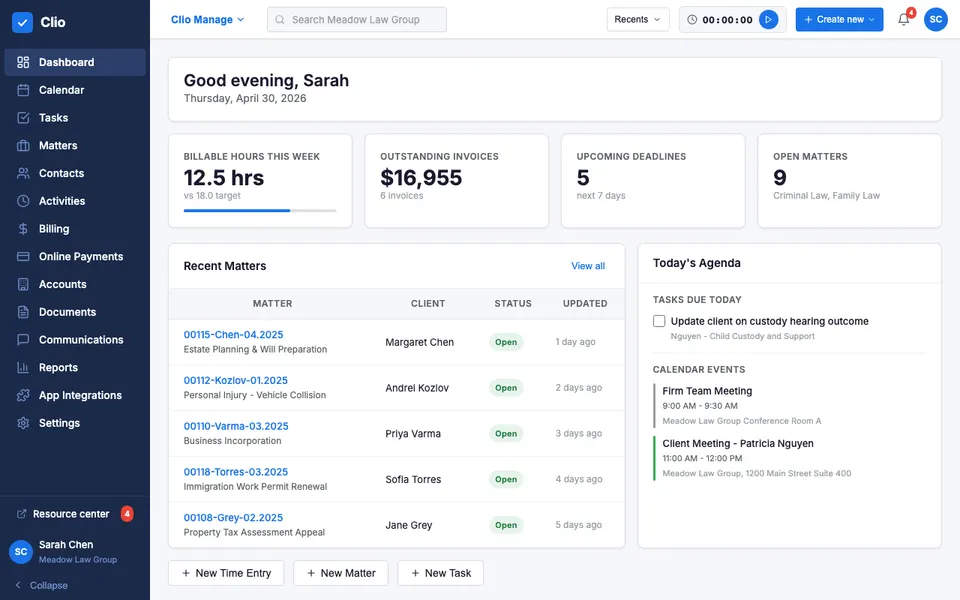
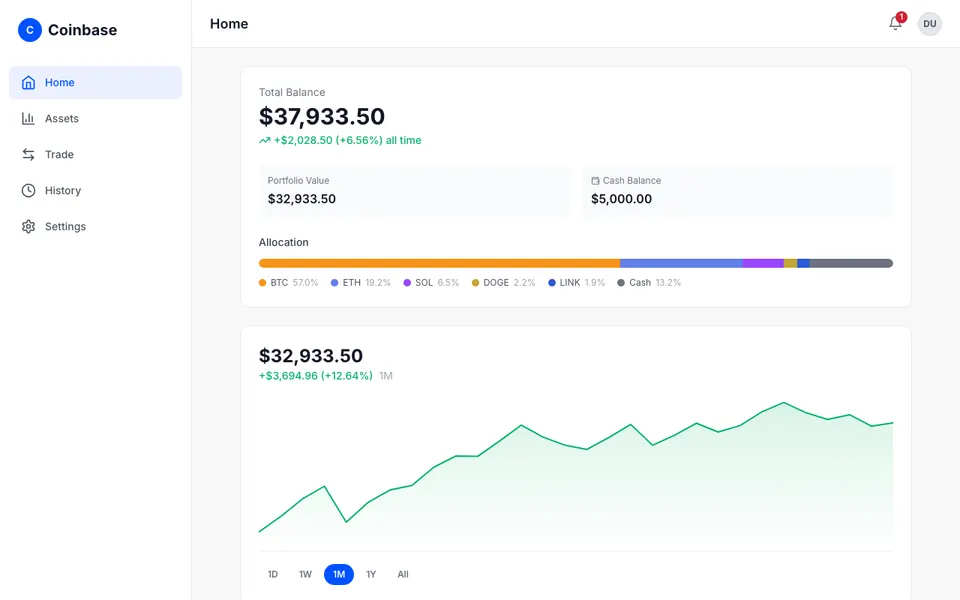
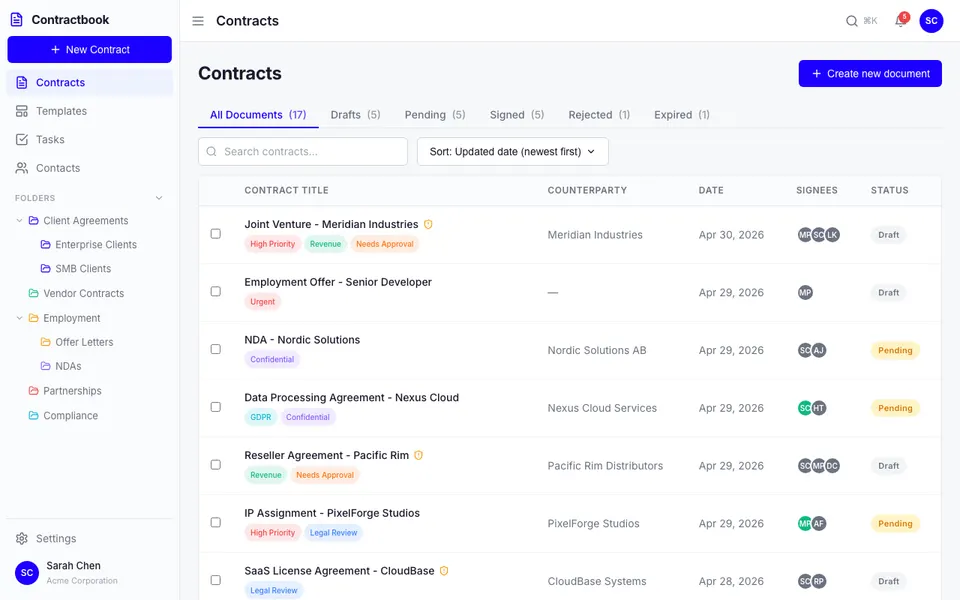
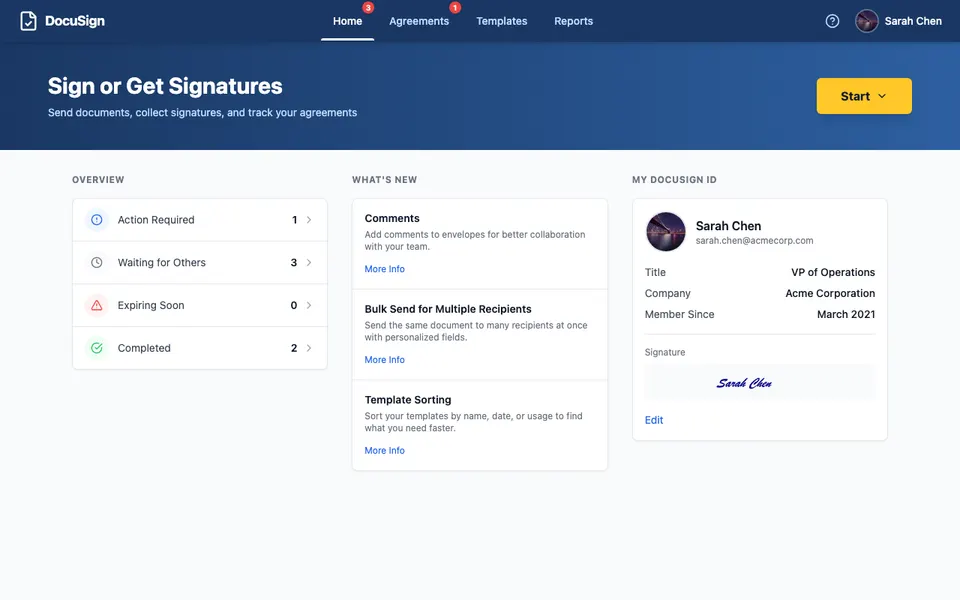
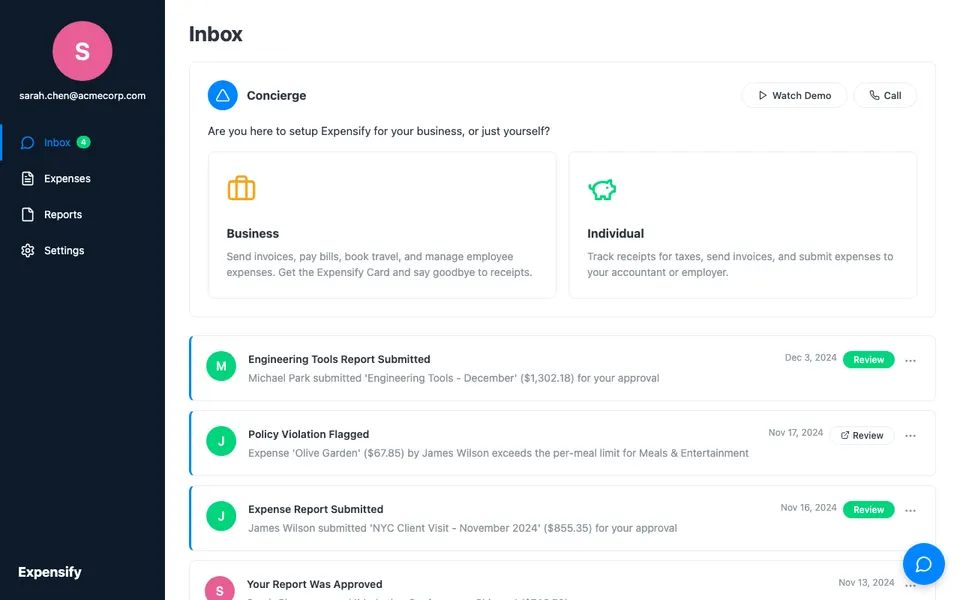
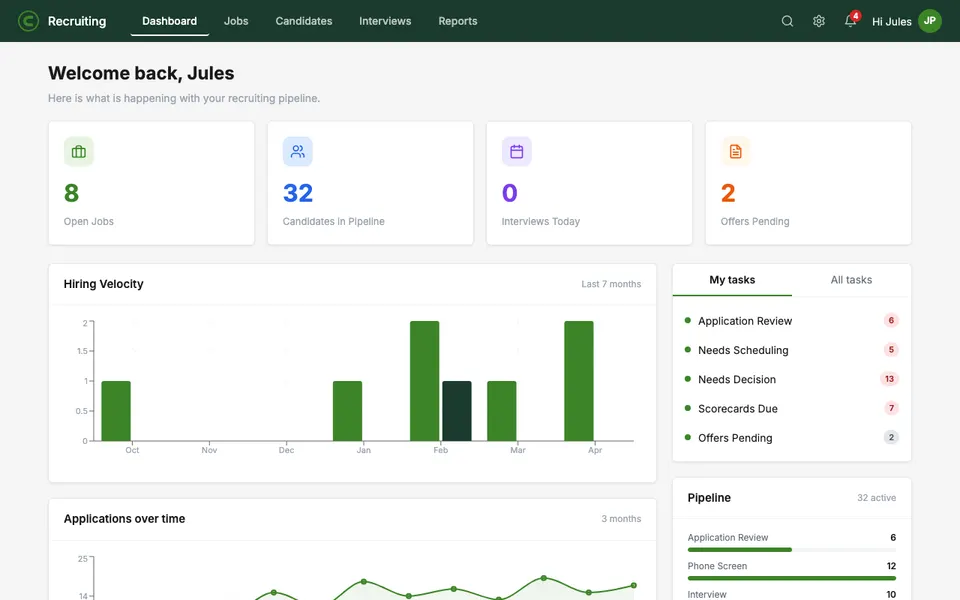
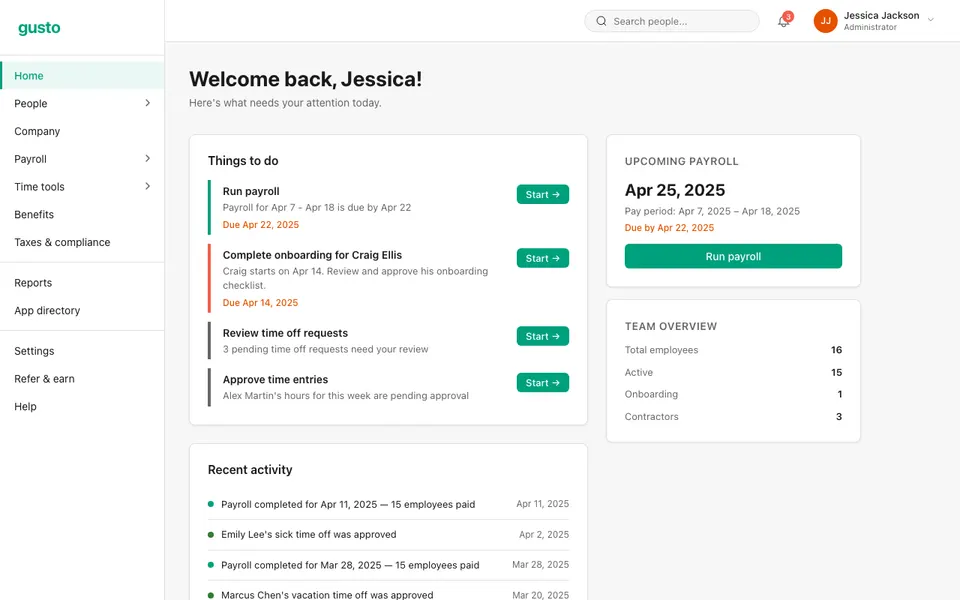
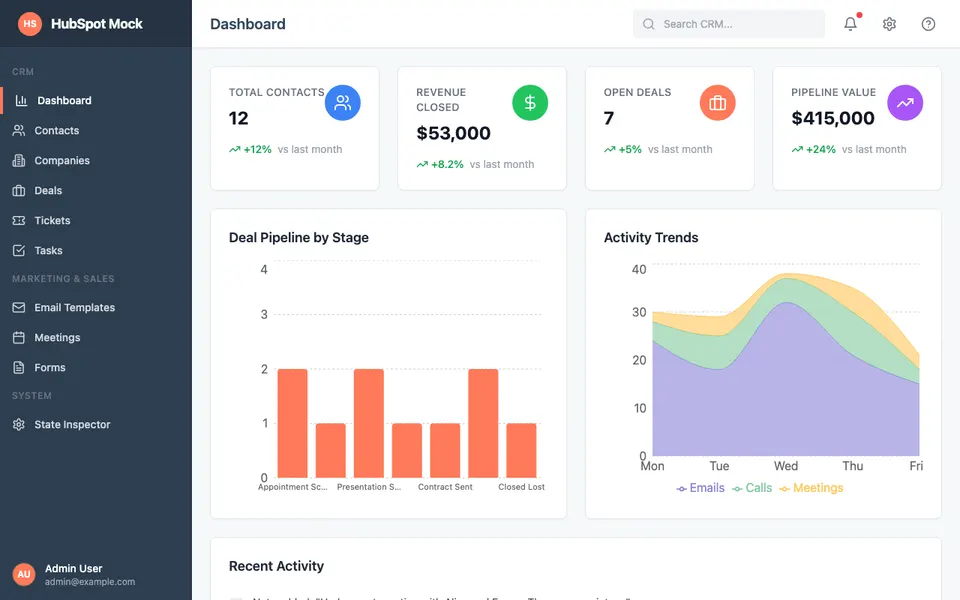
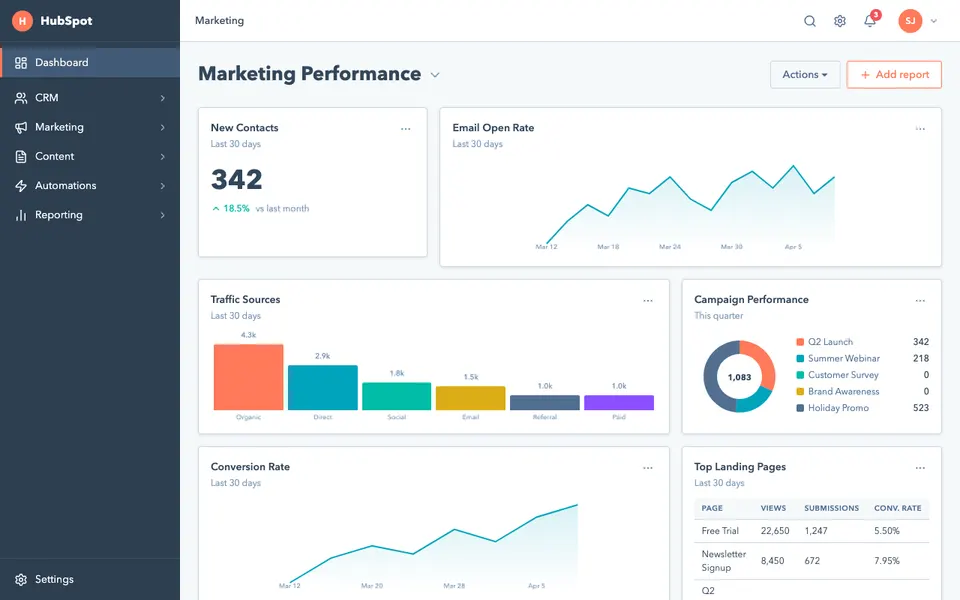
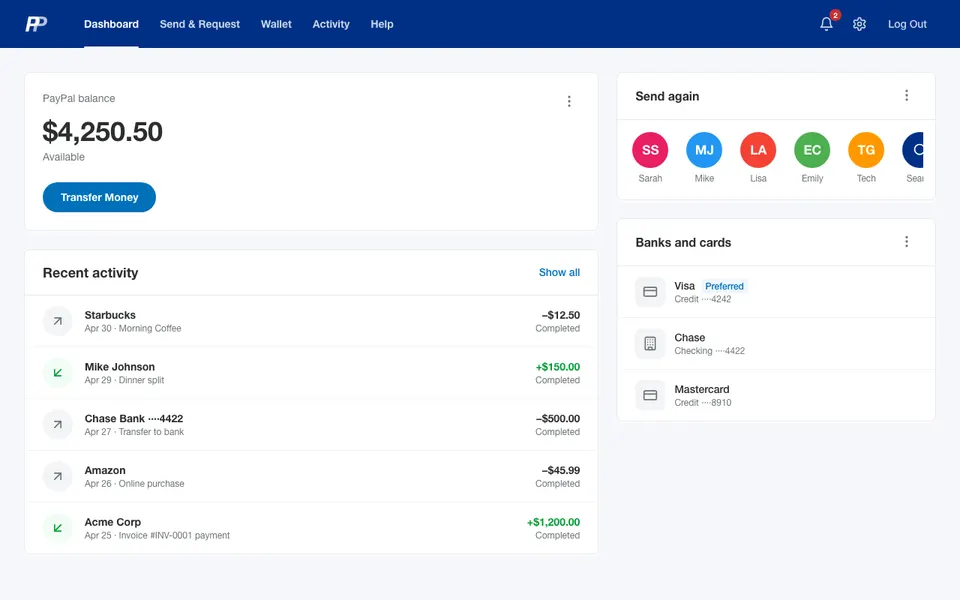
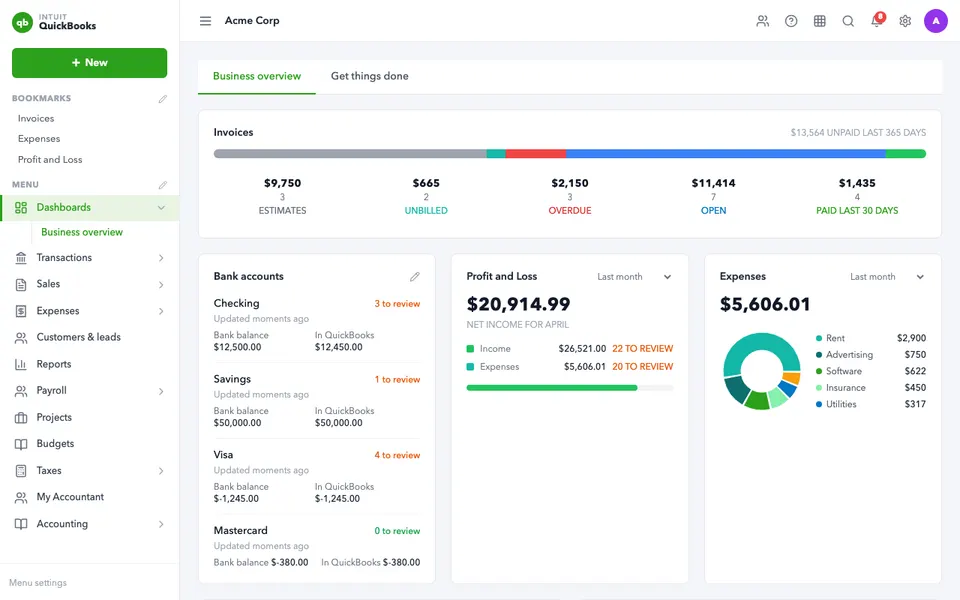
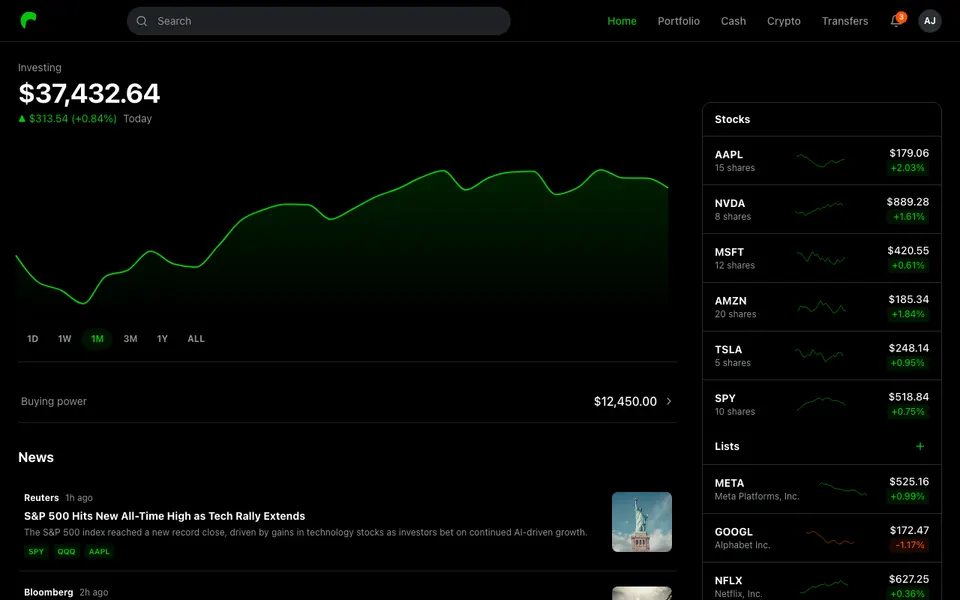
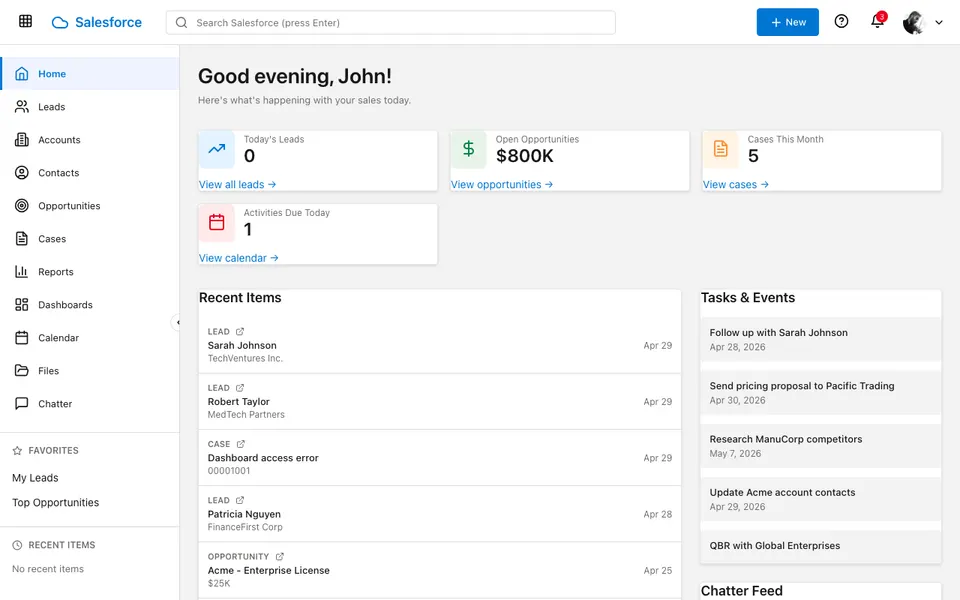
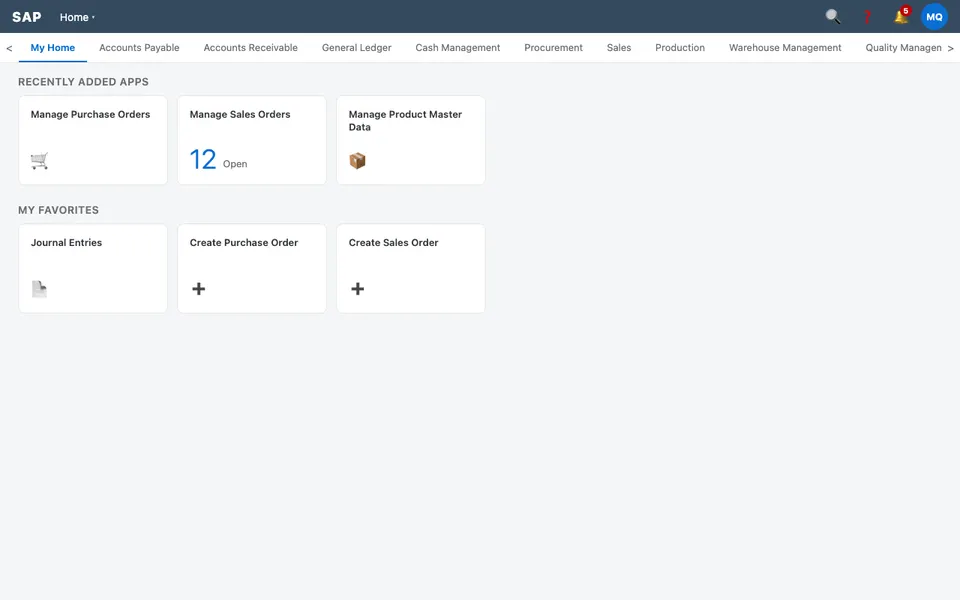
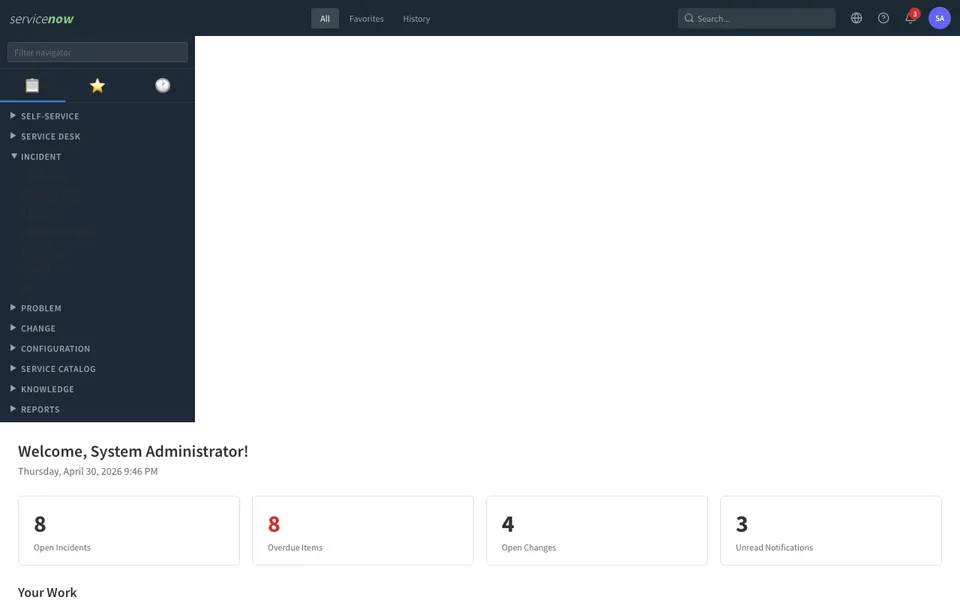
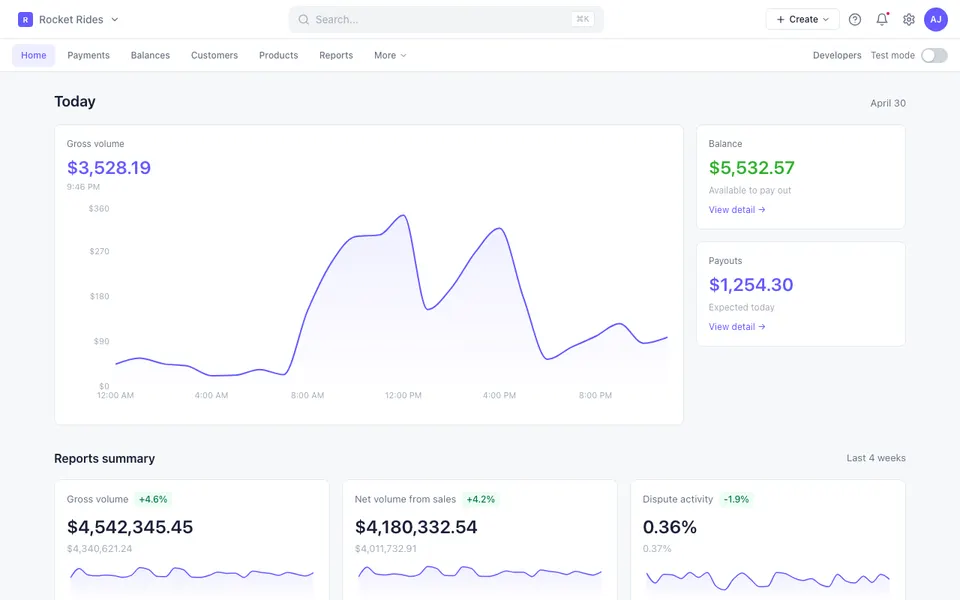
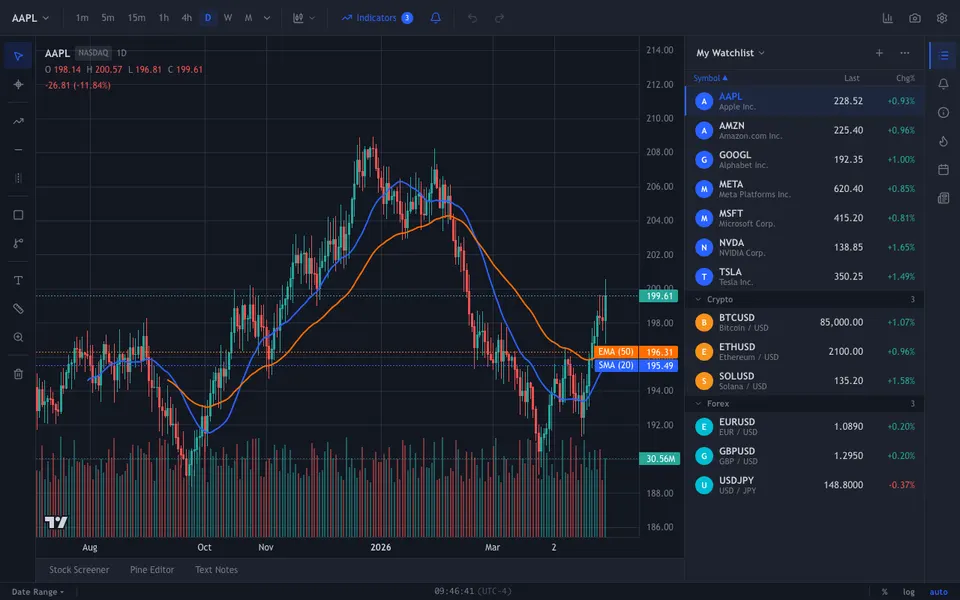
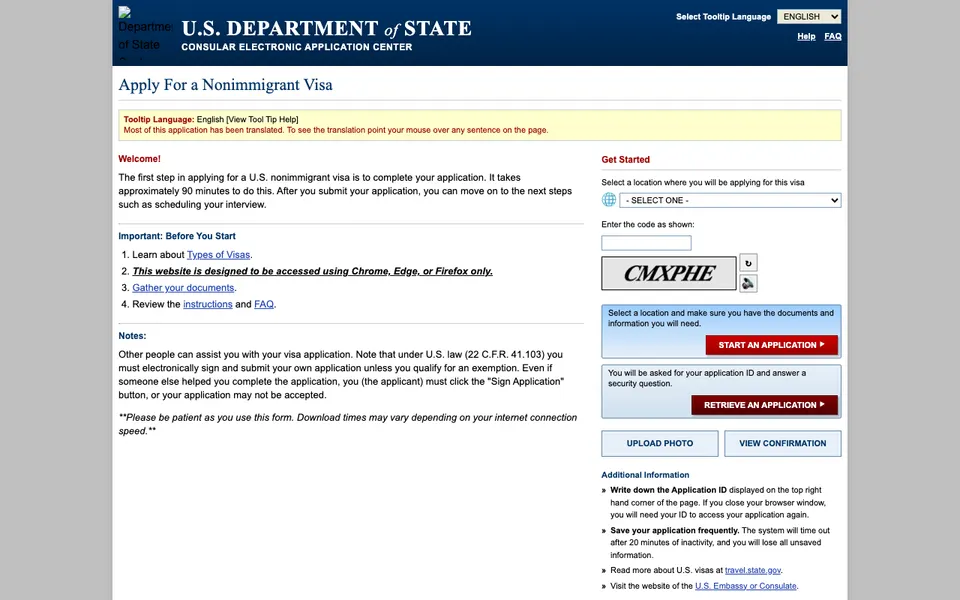
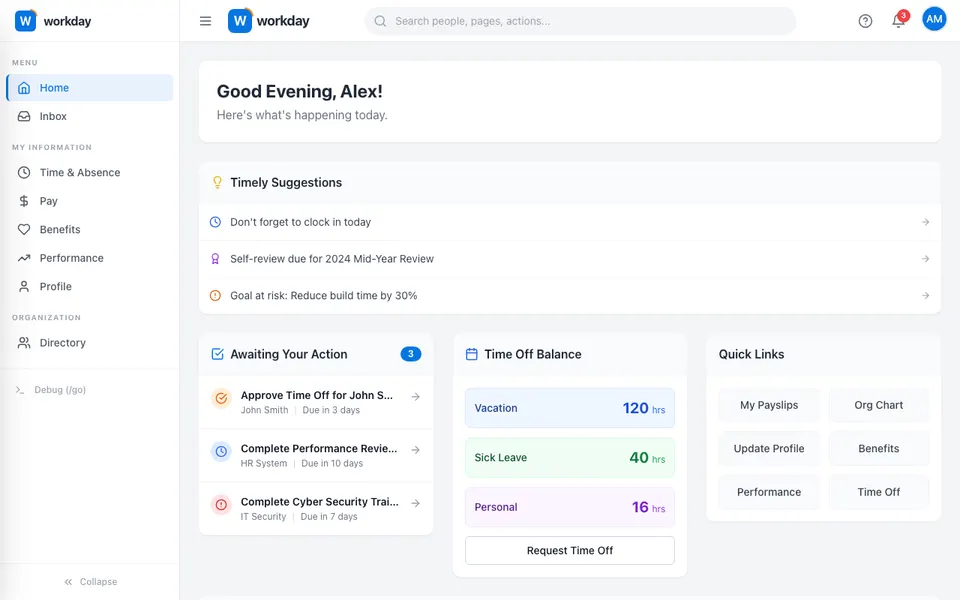
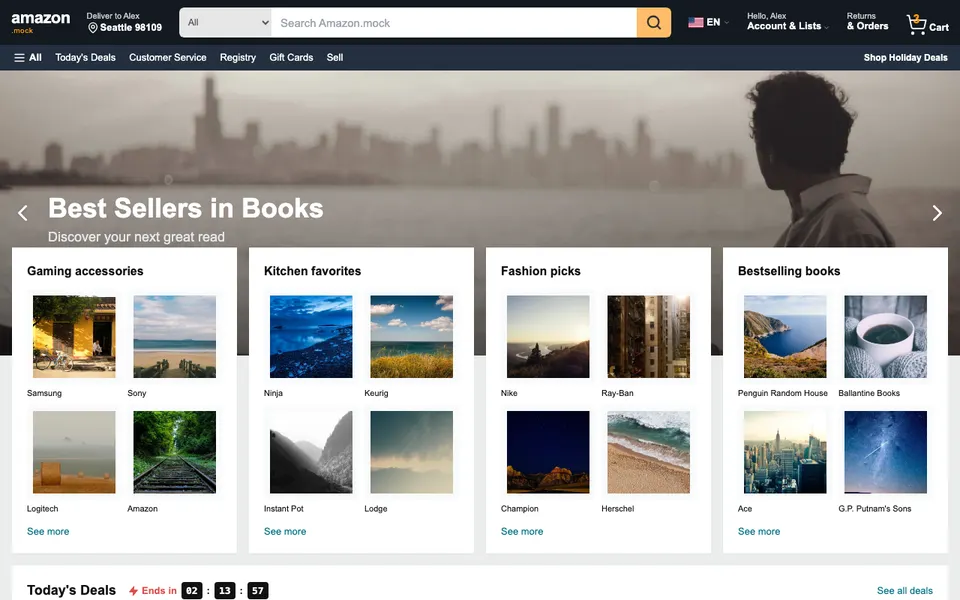
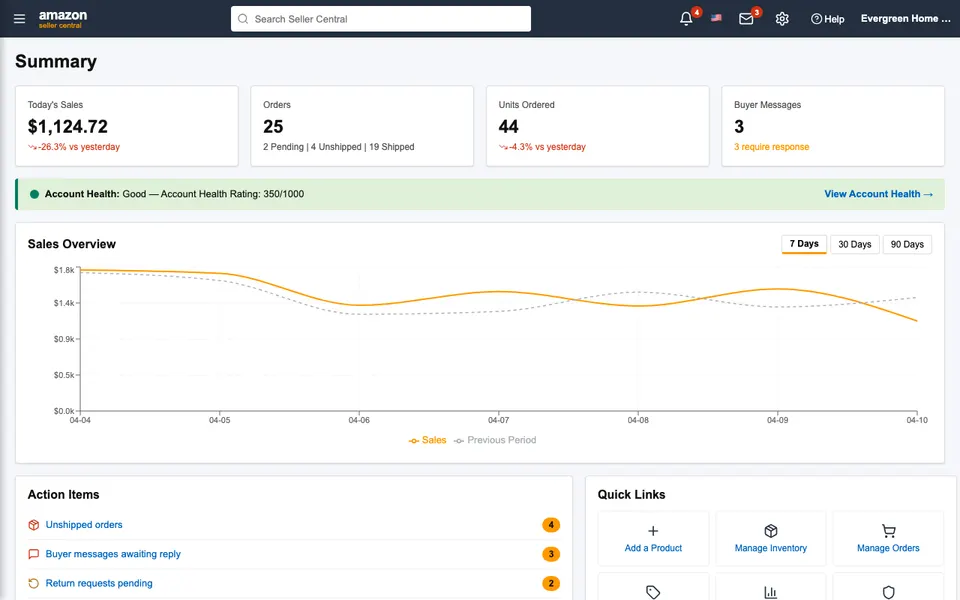
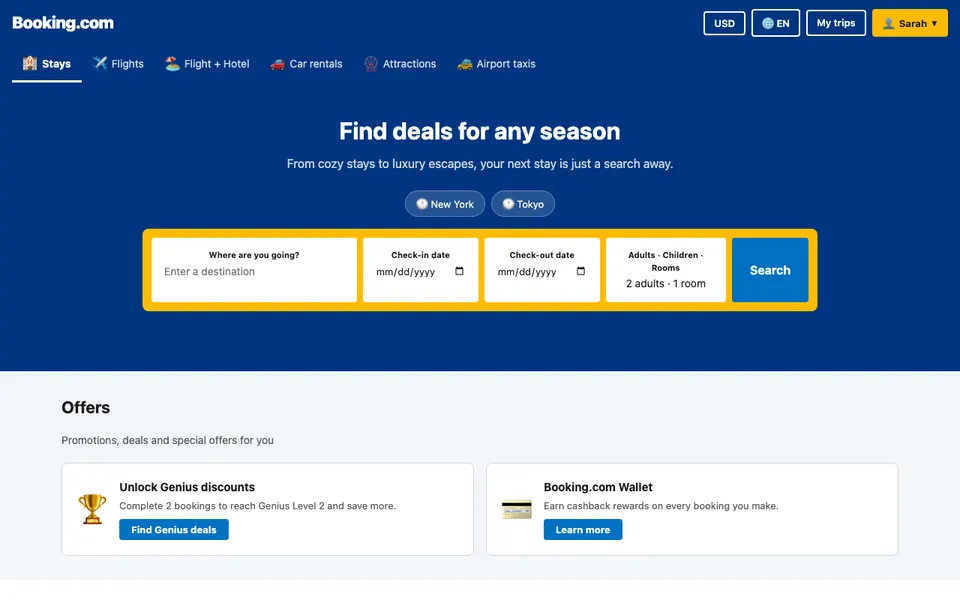
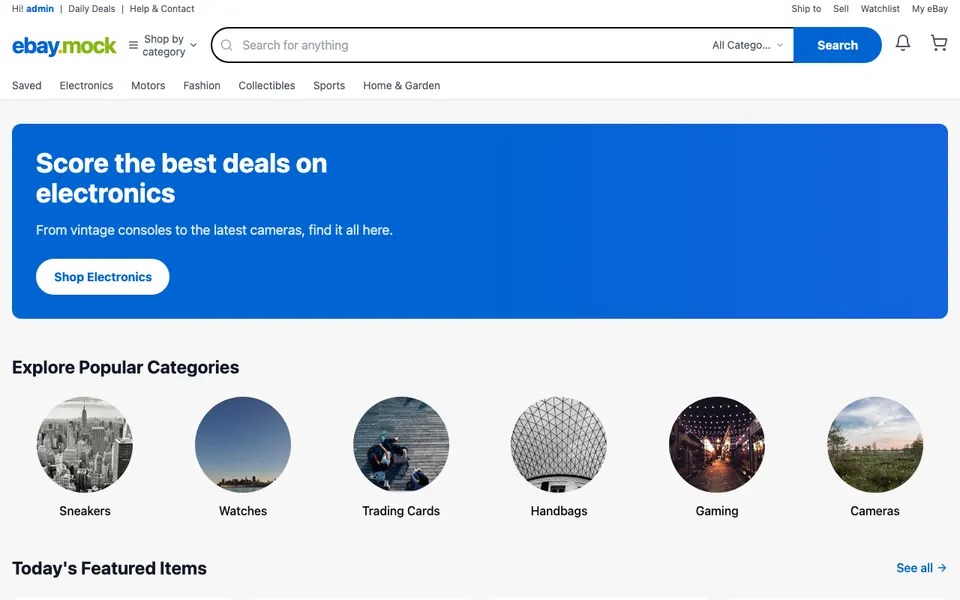
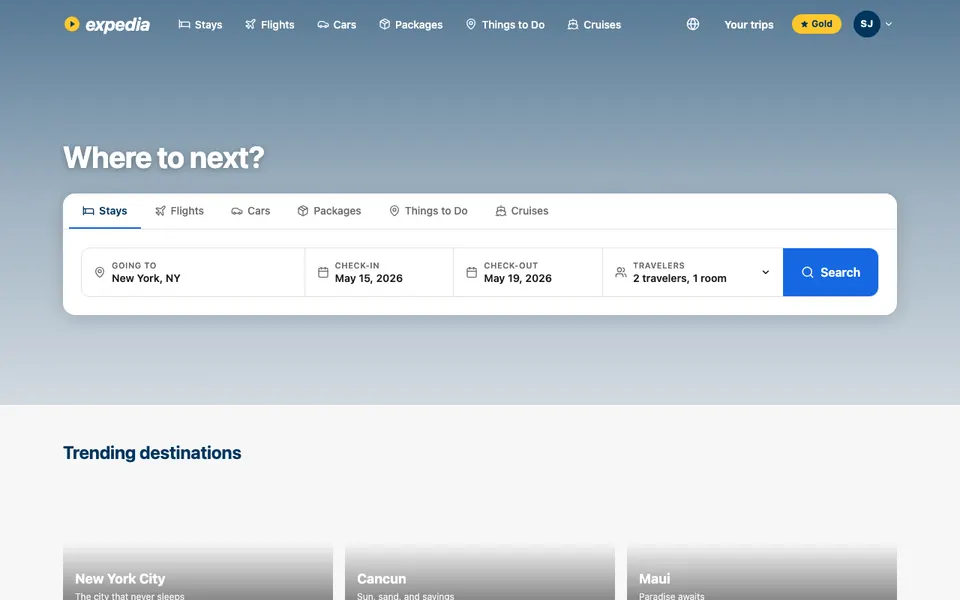
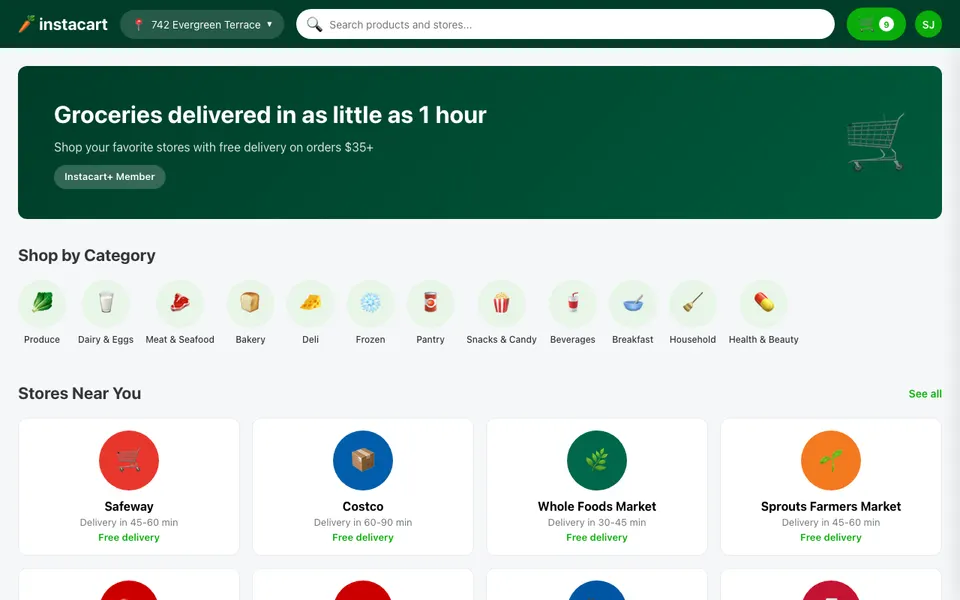
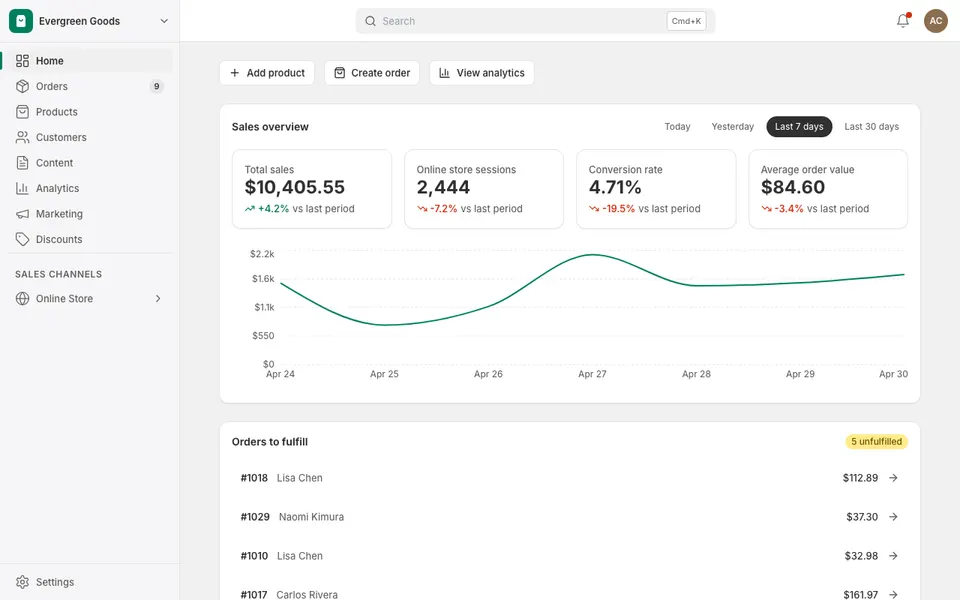
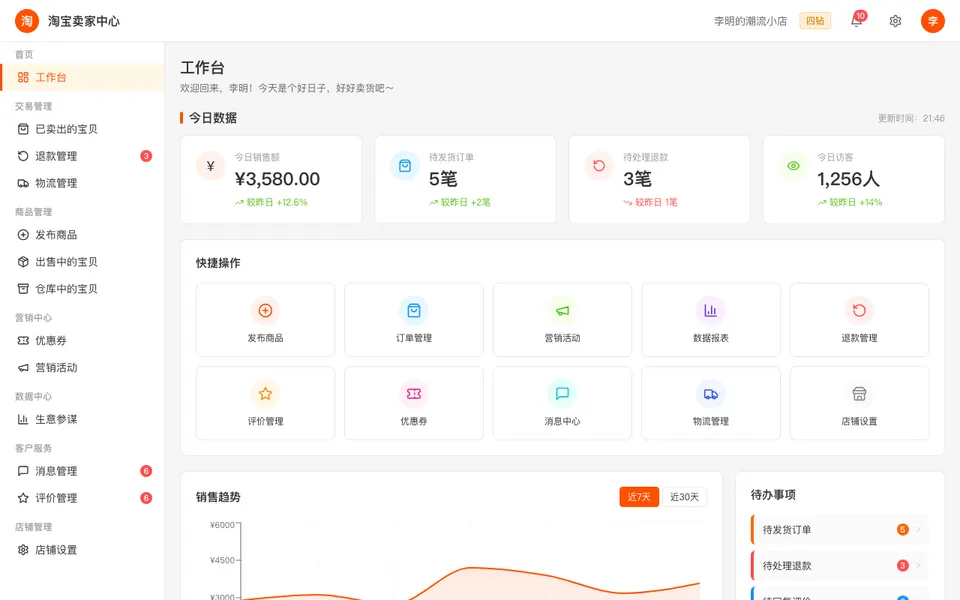
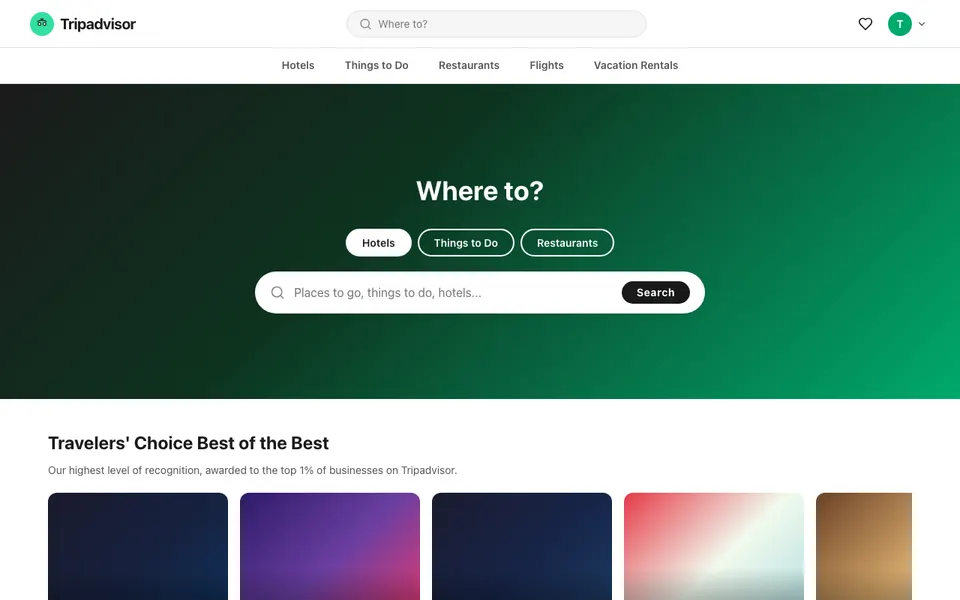
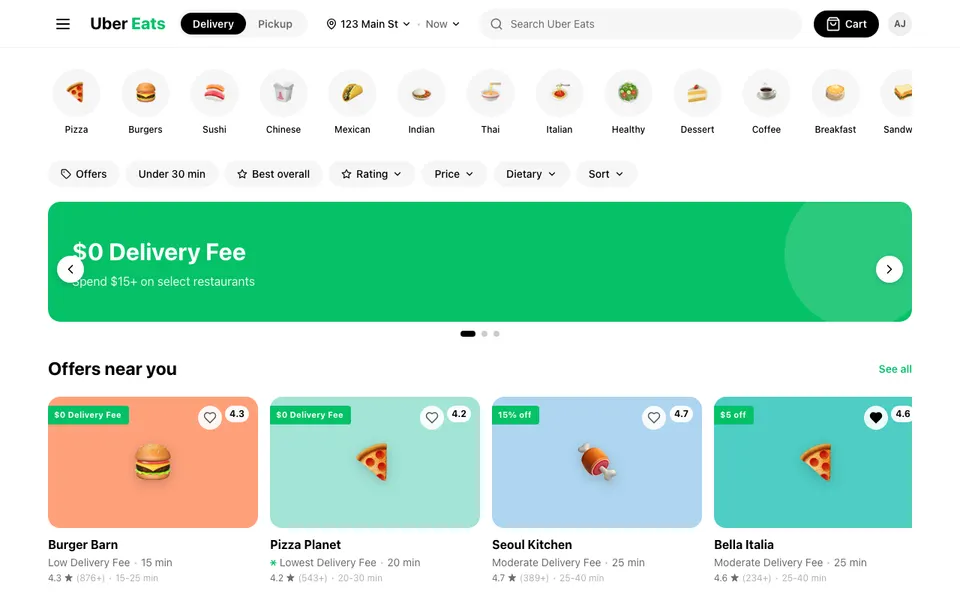
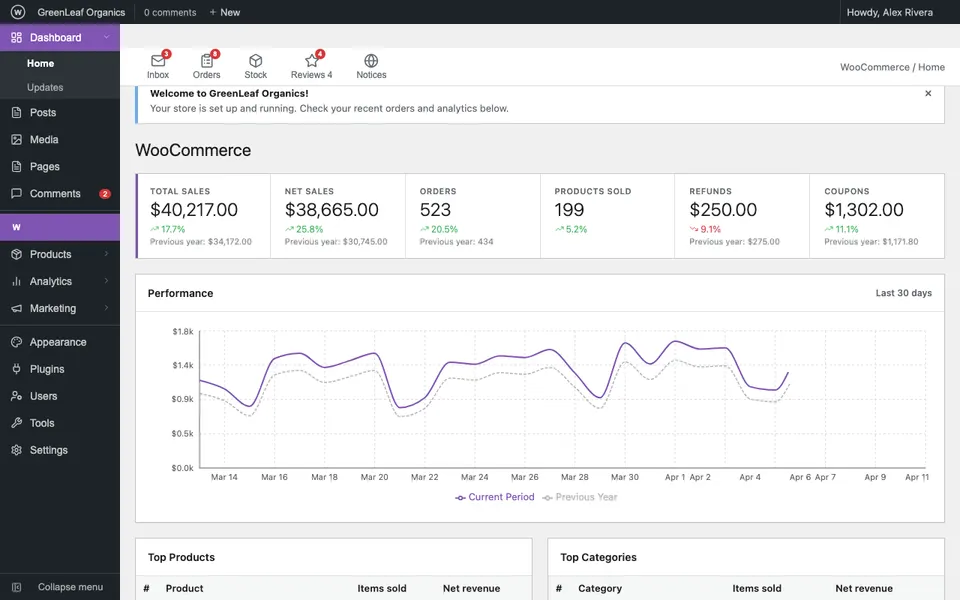
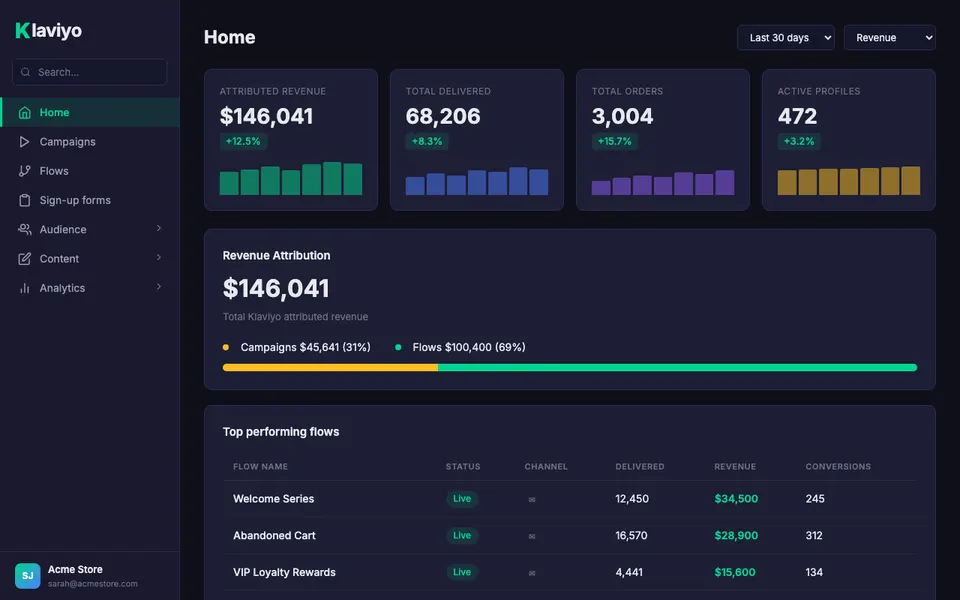
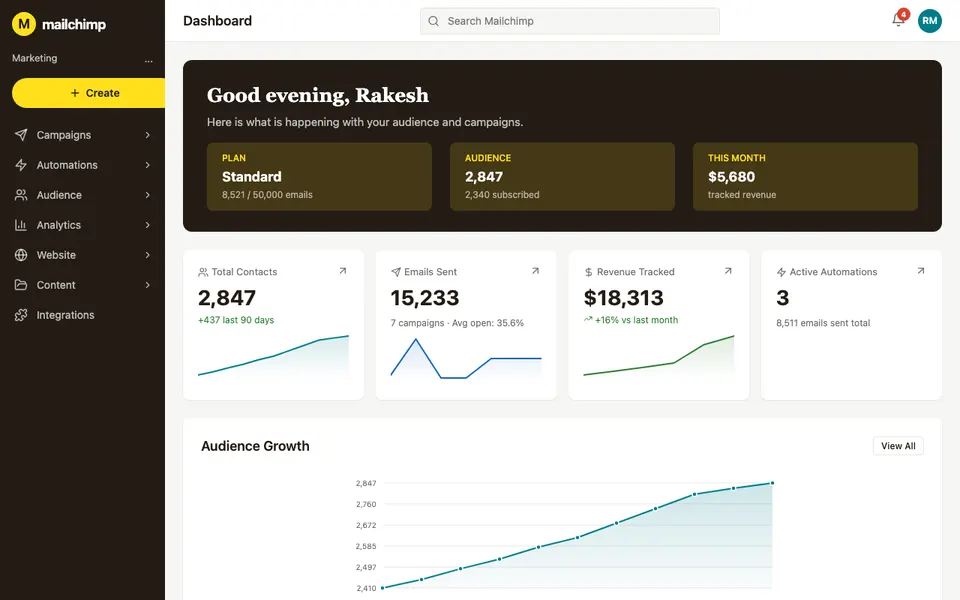
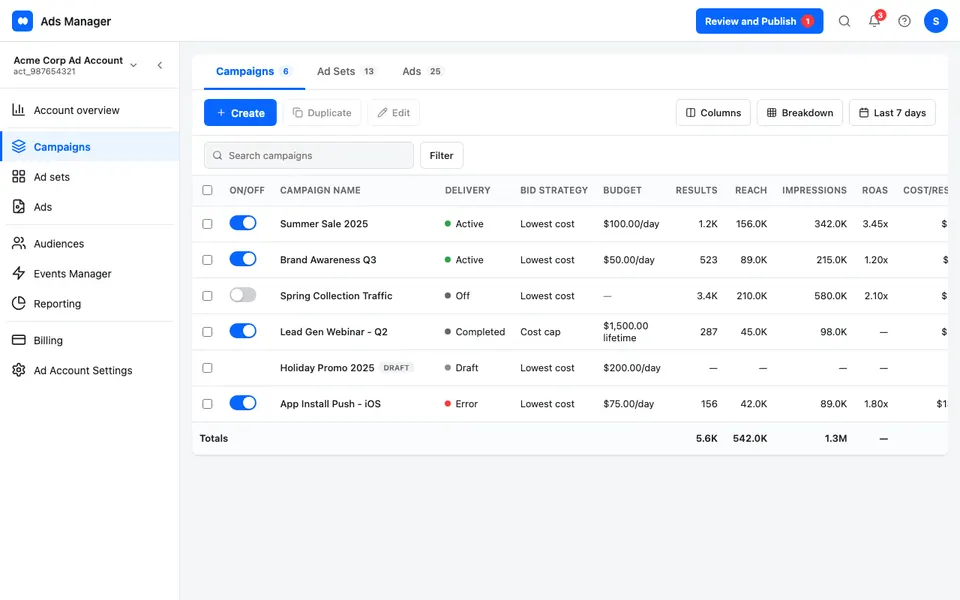
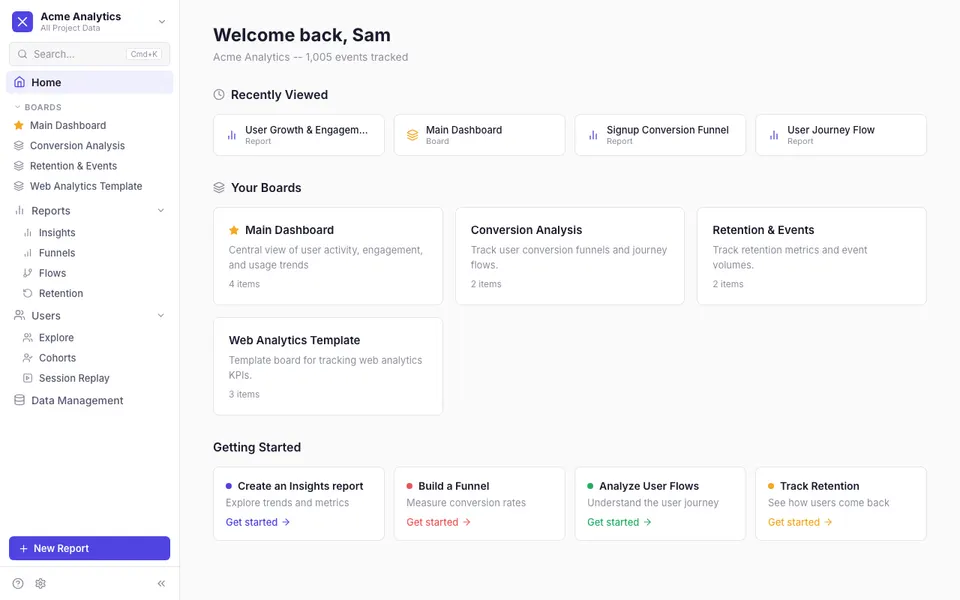
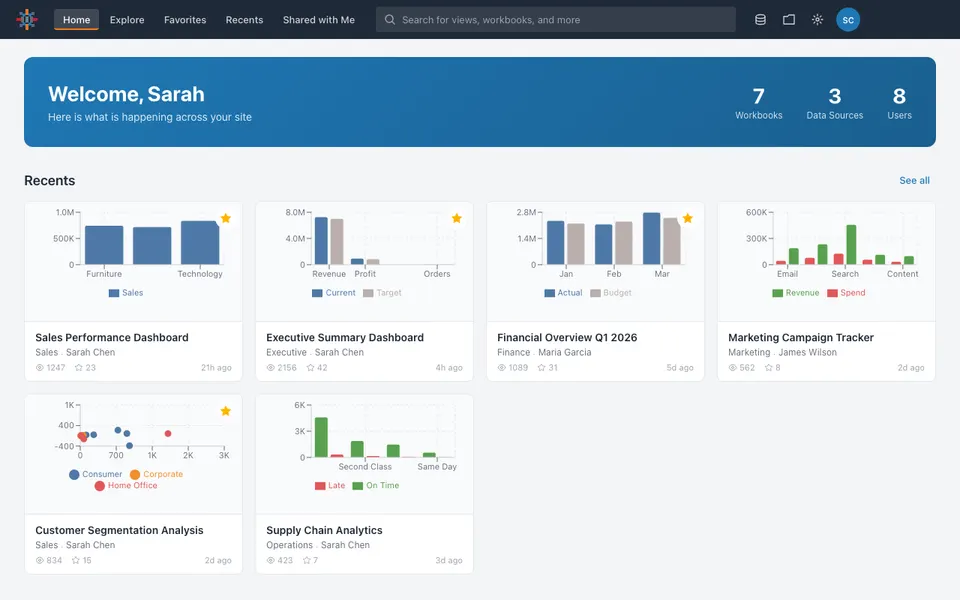
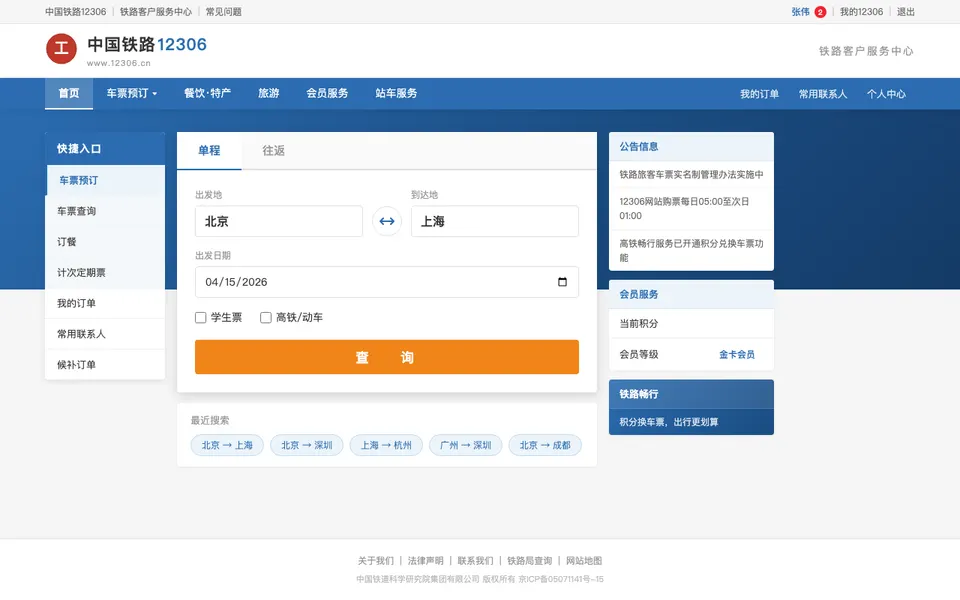
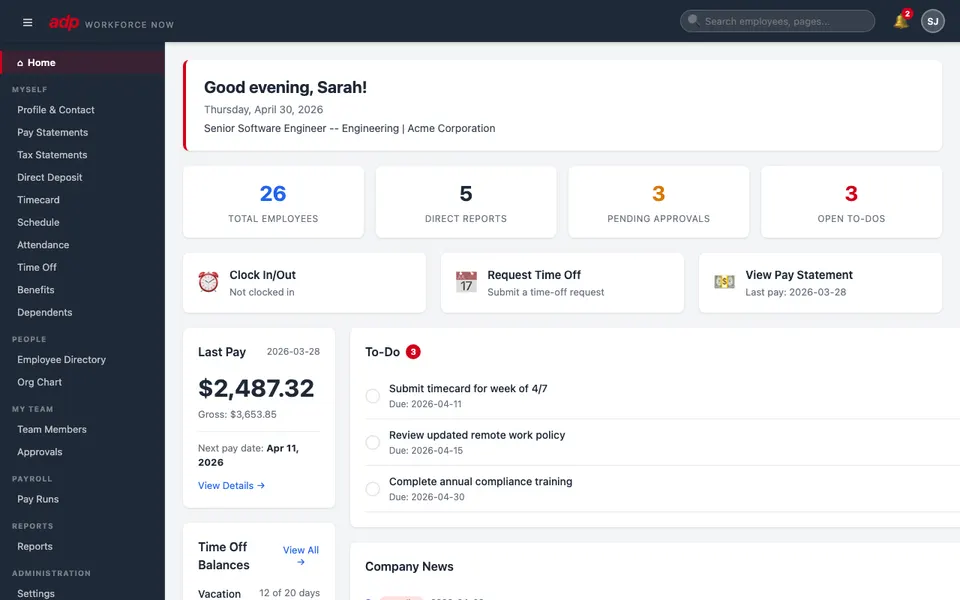
Each tuple pairs an initial_setup.py script that provisions the environment with a natural-language task and a reward.py script that verifies completion. Interactive examples with replayable trajectories are on the project homepage.
We trained two models using GSPO on the full 32K corpus: CUA-Gym-A3B on the Qwen3.5-35B-A3B base, and CUA-Gym-A17B on Qwen3.5-397B-A17B. The first result that genuinely surprised us was how much the smaller model gained. CUA-Gym-A3B lifted 35B-A3B from 54.5 to 62.1 on OSWorld-Verified, effectively matching the unmodified 397B-A17B base at roughly 10× fewer active parameters. Training had compressed a lot of capability into a much smaller compute budget.
At the larger scale, CUA-Gym-A17B pushed the 397B-A17B base from 62.2 to 70.2. Gains at this scale are typically harder to come by — the base model is already strong, and most RL recipes saturate. The fact that the improvement held, and was consistent across most domains, gave us more confidence that the data distribution was doing real work rather than just tuning to benchmark artifacts. The per-domain breakdown in Figure 4 shows the largest gains on multi-application workflows and office tools, which aligns with where the training data had the broadest coverage.
The result we were most uncertain about going in was WebArena. The training corpus has no WebArena tasks in it — only desktop apps and synthesized web mocks. But both checkpoints improve on the held-out WebArena benchmark (A3B: 40.8 to 44.5, A17B: 54.0 to 56.0), which means the mock environments are teaching something that genuinely transfers to real browser interactions, not just pattern- matching the training pool. That was the clearest validation of the synthetic sandbox approach.
- overalln=36954.5→62.1+7.6 pp
- writern=3150.0→60.0+10.0 pp
- calcn=4739.0→53.9+14.9 pp
- impressn=2255.0→60.0+5.0 pp
- gimpn=2633.0→40.0+7.0 pp
- chromen=3865.0→72.0+7.0 pp
- multi_appsn=2430.0→51.5+21.5 pp
- osn=5570.0→70.0+0.0 pp
- vs_coden=2342.0→55.6+13.6 pp
- thunderbirdn=1845.0→50.0+5.0 pp
- overalln=36062.2→70.2+8.0 pp
- writern=2365.2→91.3+26.1 pp
- calcn=4766.0→80.9+14.9 pp
- impressn=4769.1→82.8+13.7 pp
- gimpn=2650.0→61.5+11.5 pp
- chromen=4663.5→73.9+10.4 pp
- multi_appsn=9345.9→54.7+8.8 pp
- osn=2479.2→87.5+8.3 pp
- vs_coden=2268.2→68.2+0.0 pp
- thunderbirdn=1580.0→66.7-13.3 pp
| Model | OSWorld-V. | WebArena |
|---|---|---|
| Proprietary models | ||
| Claude Sonnet 4.6 | 72.9 | 65.6 |
| Claude Opus 4.7 | 78.0 | — |
| GPT-5.5 | 78.7 | — |
| Open-source models | ||
| EvoCUA-8B | 46.1 | — |
| EvoCUA-32B | 56.7 | — |
| OpenCUA-32B | 34.8 | — |
| OpenCUA-72B | 45.0 | — |
| Step-GUI-8B | 40.2 | — |
| Kimi-K2.6 | 73.1 | — |
| Ours | ||
| Qwen3.5-35B-A3B | 54.5 | 40.8 |
| Qwen3.5-397B-A17B | 62.2 | 54.0 |
| ▸CUA-Gym-A3B | 62.1 | 44.5 |
| ▸CUA-Gym-A17B | 70.2 | 56.0 |
Three things stood out from the analysis beyond the headline numbers. They each answer a question we were genuinely uncertain about going in.
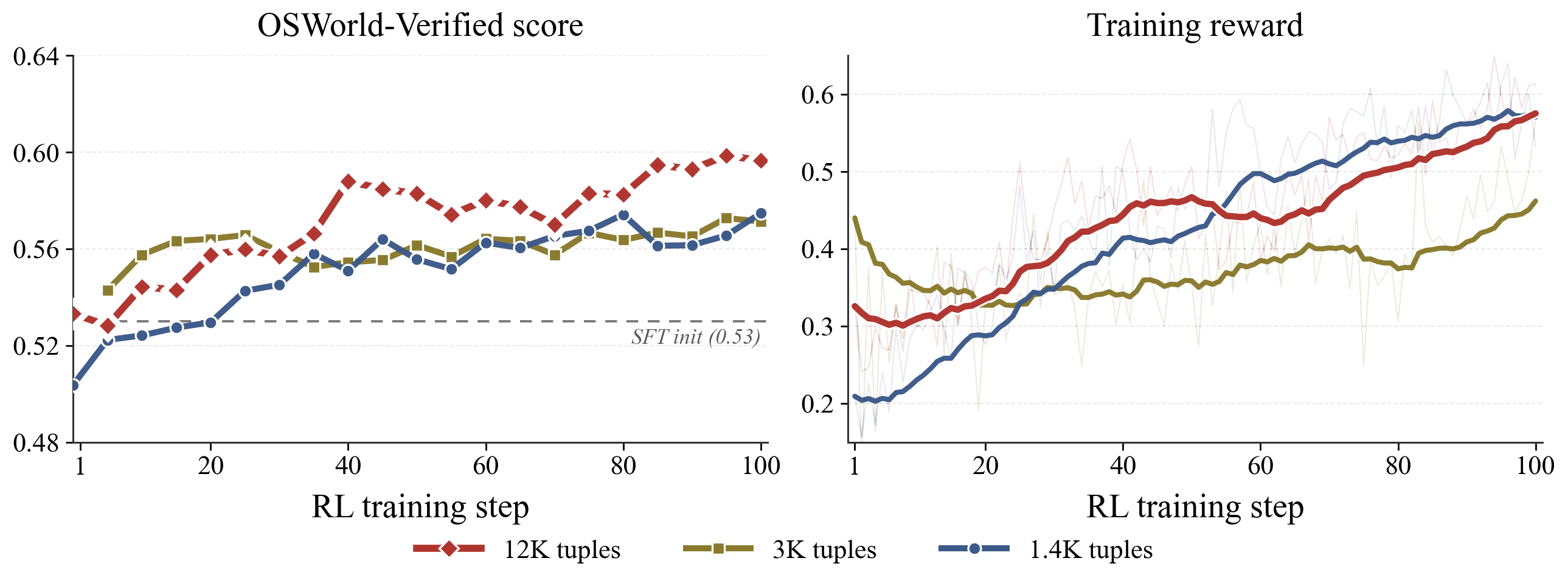
More data, cleaner signal. We ran three RL experiments at 1.4K, 3K, and 12K tuples to check whether the automated pipeline was producing reward hacking. It was not. Training reward and OSWorld success tracked together across all three scales with no oscillation or collapse, and the 12K curve was still climbing at the end of training. The information barrier was doing its job.
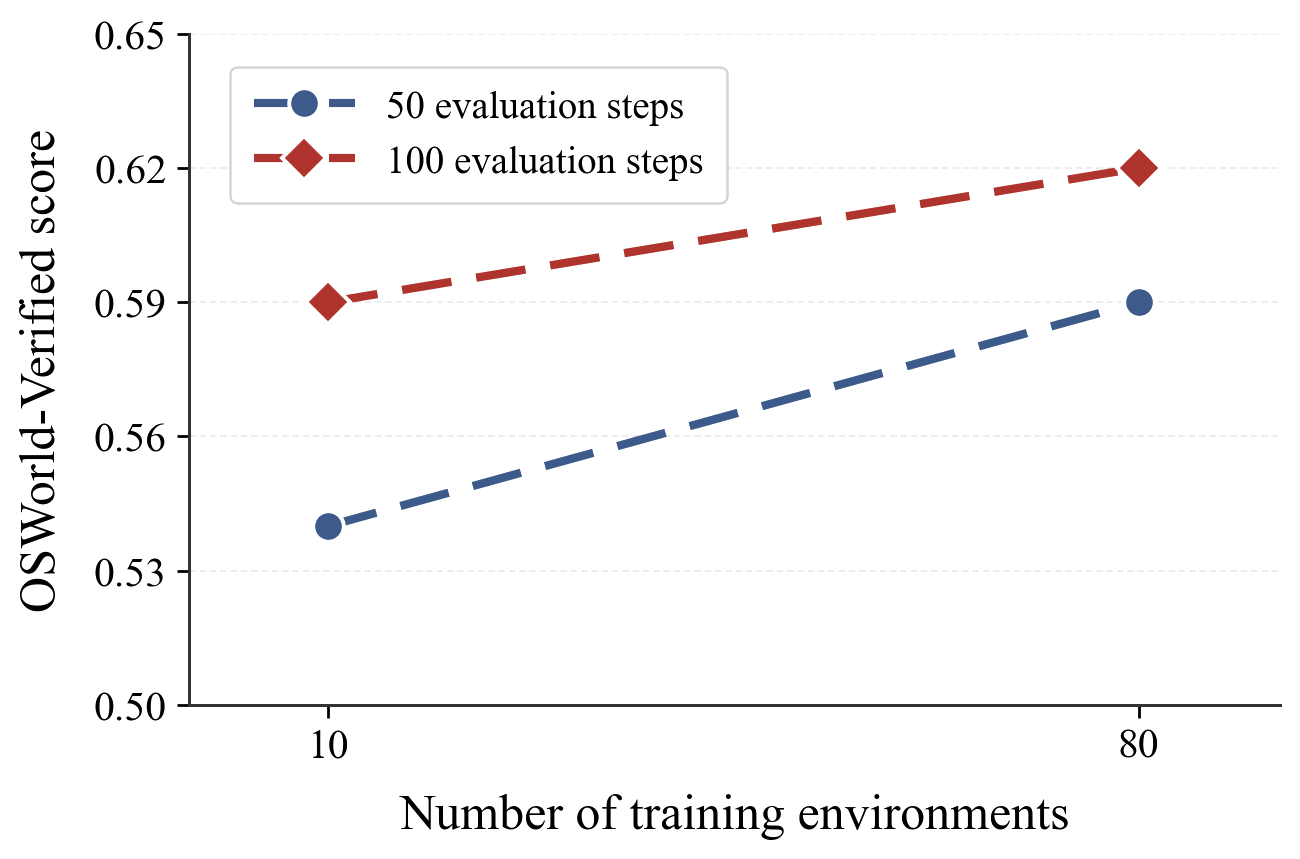
Environments and trajectories are not interchangeable. The question we wanted to answer was whether expanding to 110 environments was worth the engineering cost, or whether we could have gotten the same gains by just generating more trajectories from fewer apps. The answer was clear: environment diversity and trajectory volume improve performance along distinct axes. You cannot trade one for the other. This retroactively justified a lot of the work we put into building the mock application suite.
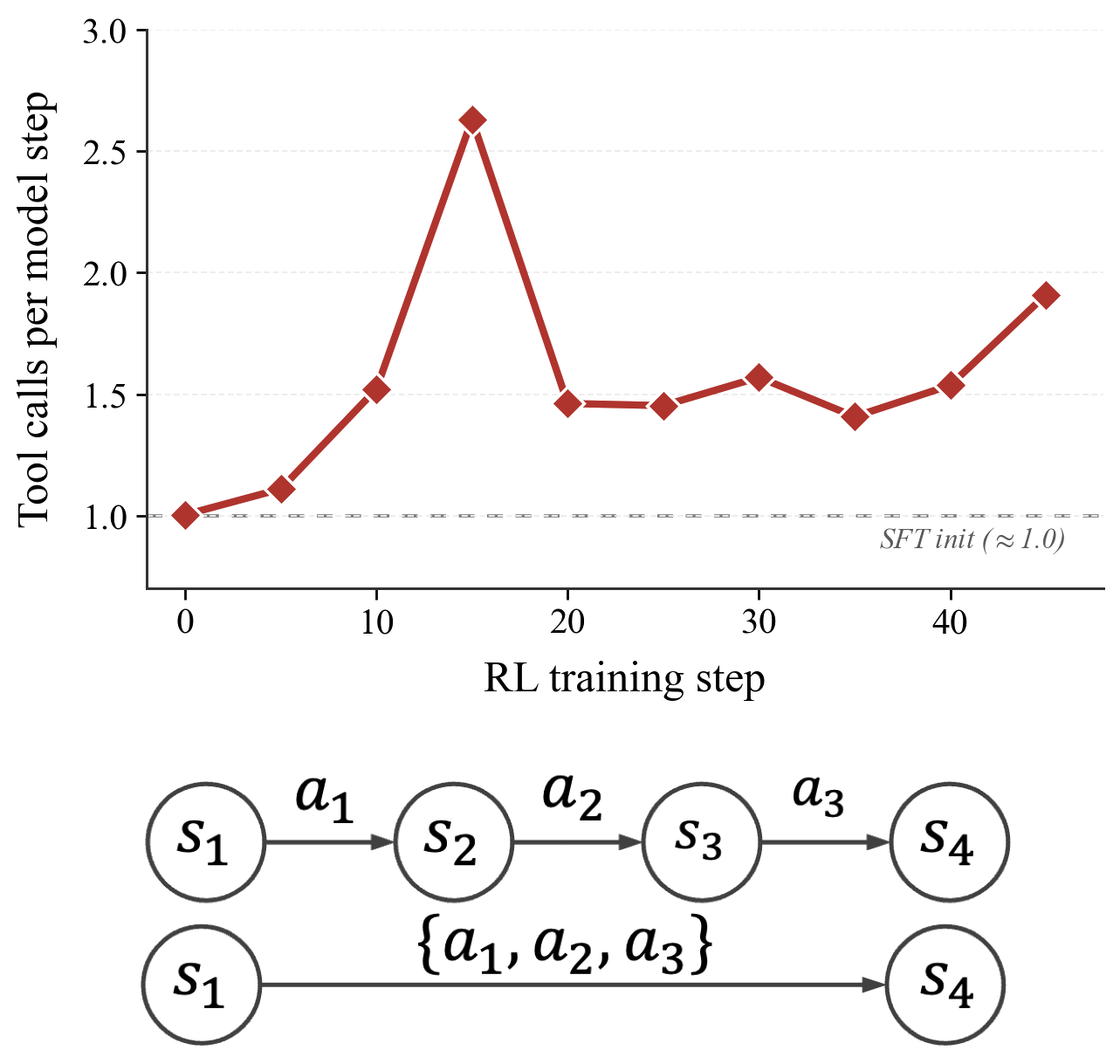
The model learned to be efficient without being asked. Partway through training, we noticed the policy was packing multiple actions into single turns — clicking through a sequence of menus in one step rather than one at a time. We never optimized for this explicitly. It emerged because RL with group-normalized rewards penalizes long trajectories relative to shorter ones that achieve the same outcome. The result was a 33 to 45 percent reduction in effective trajectory length at matched task success. It is a small reminder that RL optimizes what you measure, and sometimes finds shortcuts you did not anticipate.
The most immediate limitation is one we already flagged as a bitter lesson: the quality ceiling of CUA-Gym is currently set by the quality of its task queries, and we do not yet have a good answer for how to scale the hard ones. As base models get stronger, the tasks that are too easy for them to learn from will keep creeping upward. Generating genuinely difficult, long-horizon queries that reflect how expert users actually work — multi-step workflows that span applications, require planning, and have ambiguous intermediate states — is an unsolved problem. We think it is probably the most important next step for anyone trying to push CUA post-training further.
On the environment side, there is a version of this work that goes much deeper: building a proper open-source software sandbox ecosystem, maintained by domain experts who understand the applications well enough to write realistic state transitions and edge cases. The 94 mocks in CUA-Gym-Hub are a starting point, but they are all generated by the same pipeline with the same biases. A community-built library of training environments — closer in spirit to what OpenAI Gym was for game-playing agents — would be a meaningful infrastructure contribution to the field.
There is also a scope question we did not address. CUA as a category treats the GUI as the primary interaction surface, but real knowledge workers move fluidly between graphical interfaces and the command line — writing a script, running a query, editing a config file, then switching back to a browser. Modeling this as a unified problem and training an agent that reasons about both surfaces together feels like the right long-term framing, and CUA-Gym's data format is general enough to support it.
Finally, two things we want to pursue with CUA-Gym as the platform. First, the RL rollout infrastructure for GUI agents is still immature: environment reset latency, parallel rollout management, and reward evaluation throughput are all bottlenecks that limit how fast the training loop can run. Better tooling here would benefit everyone working in this space. Second, we have only scratched the surface of the RLVR recipe itself — reward shaping, curriculum design, group composition strategies — and CUA-Gym is a controlled enough environment to run real ablations on these questions. We are planning to use it exactly that way.
If you find CUA-Gym useful, please cite:
@article{cuagym2026,
title = {CUA-Gym: Scaling Verifiable Training Environments
and Tasks for Computer-Use Agents},
author = {Anonymous},
journal = {arXiv preprint},
year = {2026},
}